Kafka专题

Kafka专题
Write by MiaoJiawei 2022年2月18日 18点36分
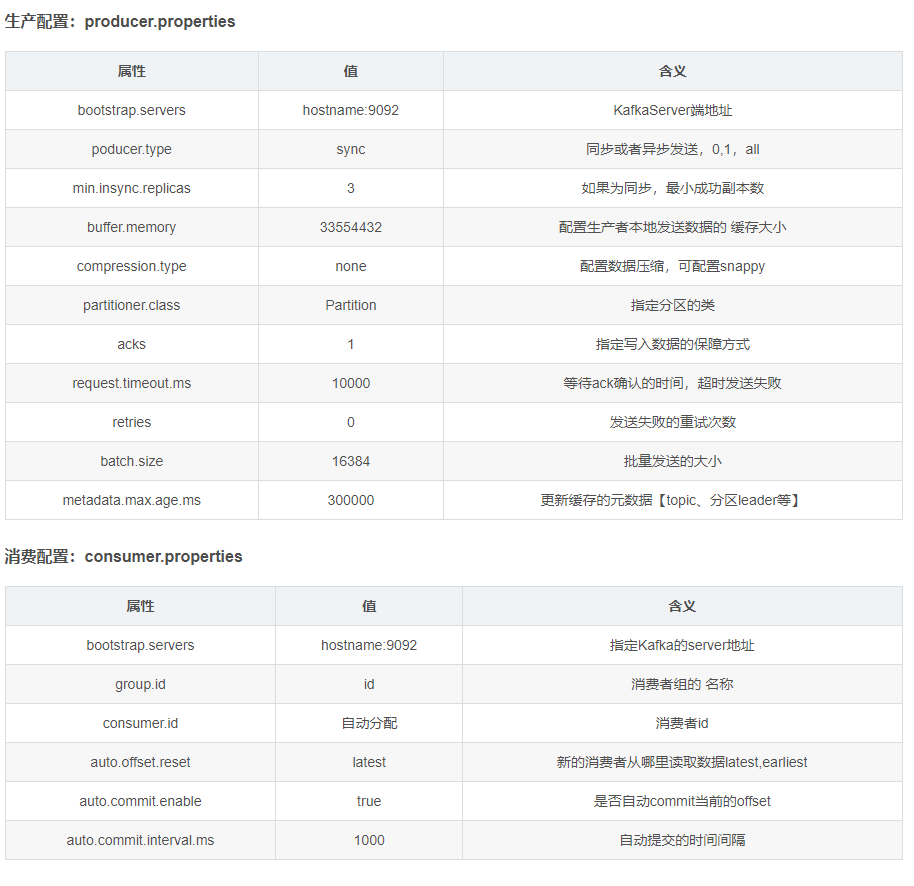
1. 消息队列
消息队列是什么?
- 消息队列是一种异步的服务间通信方式,是分布式系统中重要的组件,主要解决应用耦合,异步消息,流量削锋等问题,实现高性能,高可用,可伸缩和最终一致性架构。
- 简单点说:消息队列MQ用于实现两个系统之间或者两个模块之间传递消息数据时,实现数据缓存
功能
- 基于队列的方式,实现数据缓存
应用场景
- 用于所有需要实现实时、高性能、高吞吐、高可靠的消息传递架构中
优点
- 实现了架构解耦
- 保证了最终一致性
- 实现异步,提供传输性能
缺点
- 增加了消息队列,架构运维更加复杂
- 数据一致性保证更加复杂,必须保证生产安全和消费安全
同步与异步
同步的流程
step1:用户提交请求
step2:后台处理请求
step3:将处理的结果返回给用户
特点:用户看到的结果就是我处理好的结果
场景:去银行存钱、转账等,必须看到真正处理的结果才能表示成功,实现立即一致性
异步的流程
step1:用于提交请求
step2:后台将请求放入消息队列,等待处理,返回给用户一个临时结果
step3:用户看到临时的结果,真正的请求在后台等待处理
特点:用户看到的结果并不是我们已经处理的结果
场景:用户暂时不需要关心真正处理结果的场景下,只要保证这个最终结果是用户想要的结果即可,实现最终一致性
2. Kafka的组件
2.1 kafka的架构图
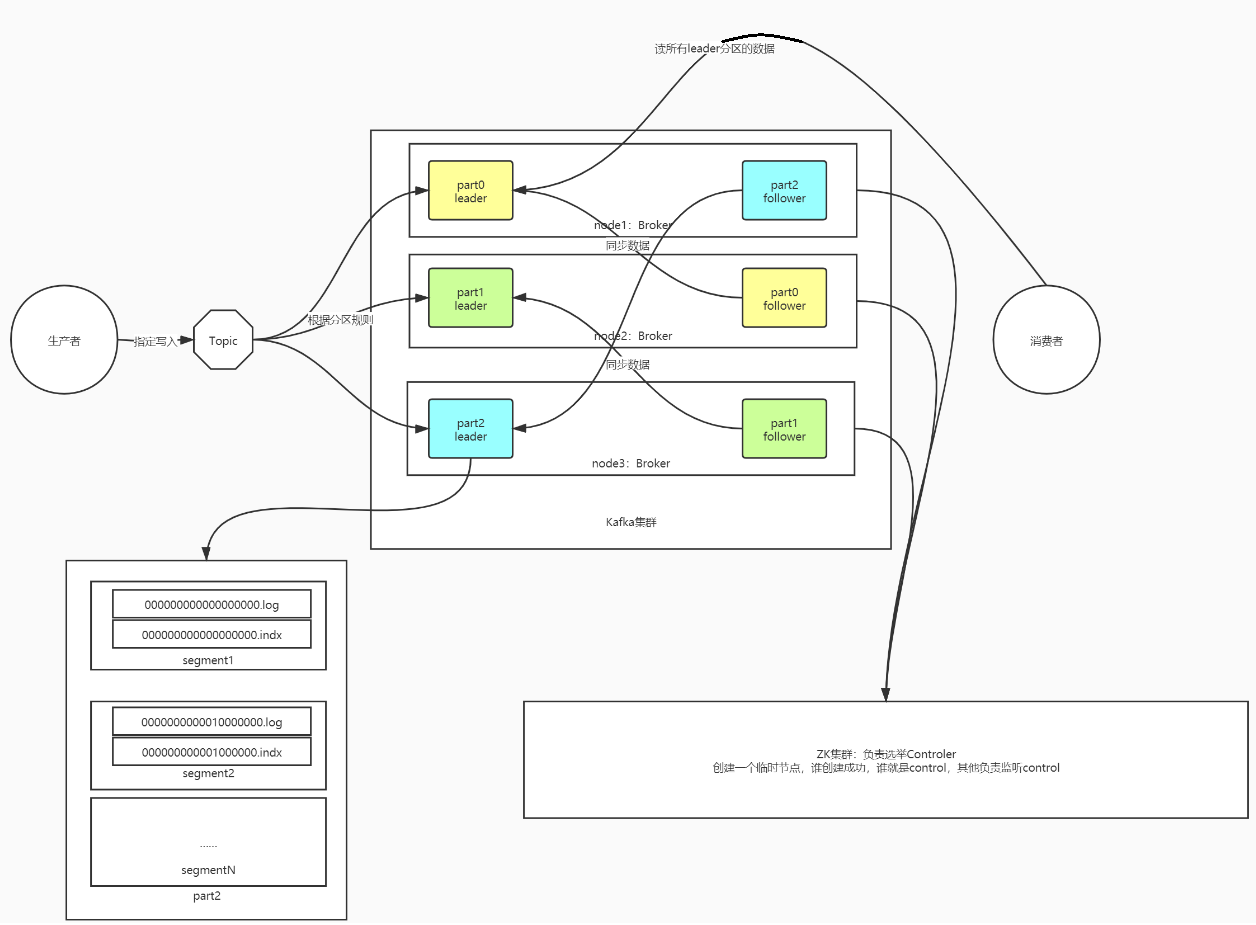
2.2 kafka的Producer、Consumer、Consumer Group、Broker
- Producer:生产者,负责写入数据到Kafka
- Consumer:消费者,负责从Kafka消费读取数据
- Consumer Group:消费者组:Kafka中的数据消费必须以消费者组为单位
- 一个消费者组可以包含多个消费者,注意多个消费者消费的数据加在一起是一份完整的数据
- 目的:提高性能
- 消费者组消费Topic
- 消费者组中的消费者消费Topic的分区
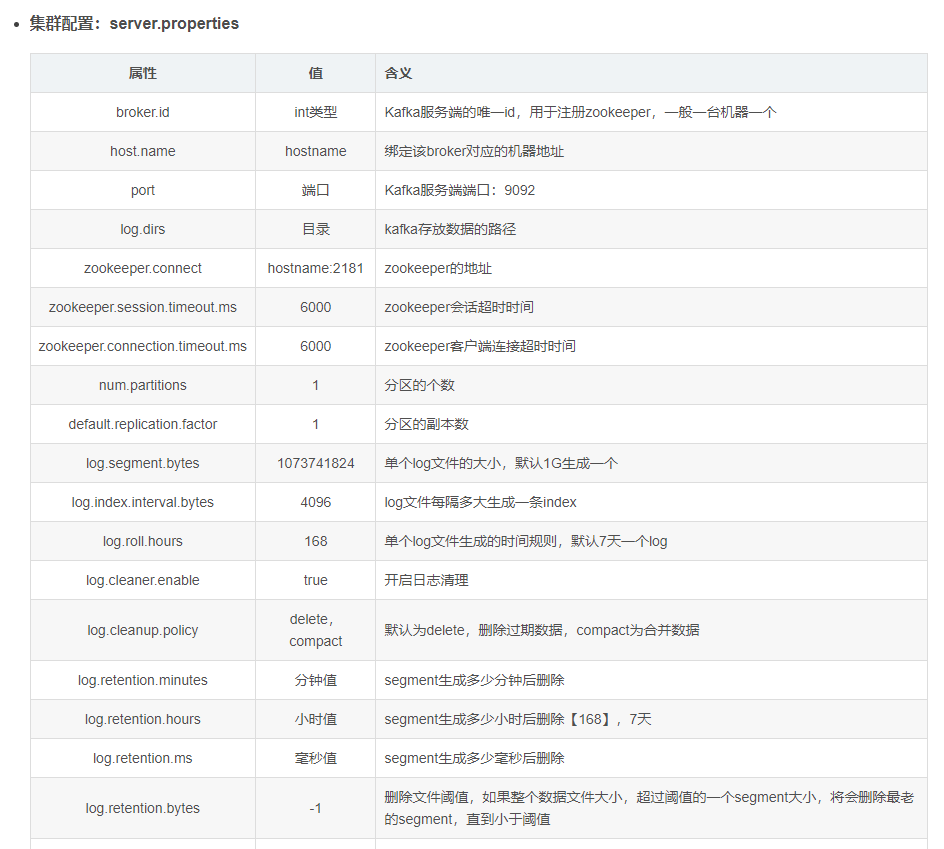
- Broker:Kafka一个节点,多个Broker节点,构建为一个Kafka集群
- 主从架构:类似于【Zookeeper】、【HDFS:NameNode、DataNode】、【Hbase:HMaster、HRegionServer】
- Kafka:Kafka
- 主:Kafka Controller:管理集群中的Topic、分区、副本选举
- 从:Kafka Broker:对外接受读写请求,存储分区数据
- 启动Kafka时候,会从所有的Broker选举一个Controller,如果Controller故障,会从其他的Broker重新选举一个
- 选举:使用ZK是实现辅助选举
- Zookeeper
- 辅助选举Active的主节点:Crontroller
- 存储核心元数据
2.3 kafka的Topic、Partition、Replication
Topic:逻辑上实现数据存储的分类,类似于数据库中的表概念
Partition:Topic中用于实现分布式存储的物理单元,一个Topic可以有多个分区
Replication:每个分区可以存储在不同的节点,实现分布式存储
Replication副本机制:Kafka中每个分区可以构建多个副本【副本个数 <= 机器的个数】
将一个分区的多个副本分为两种角色
leader副本:负责对外提供读写请求
follower副本:负责与leader同步数据,如果leader故障,follower要重新选举一个成为leader
副本角色的选举:不由ZK实现选举,由Kafka Crontroller来决定谁是leader
2.4 kafka的Offset
- Offset是kafka中存储数据时给每个数据做的标记或者编号
- 分区级别的编号
- 从0开始编号
- 功能:消费者根据offset来进行消费,保证顺序消费,数据安全
2.5 kafka的Segment
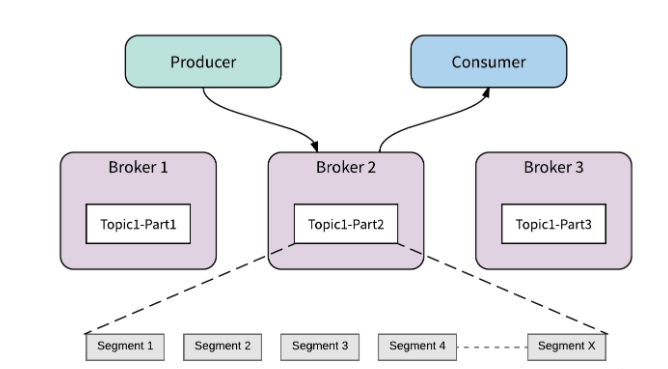
Segment的作用:对分区内部的数据进行更细的划分,分区段,文件段
- 类似于Region中划分store
规则:按照文件产生的时间或者大小
目的:提高写入和查询性能,增加删除效率:避免一条一条删除,按照整个Segment进行删除
Segment的命名规则:用最小的offset命名的,可以用于检索数据
组成:每个Segment由两个文件组成(真正在broker磁盘上的路径:topic-partiotion/.log&.index)
- .log:存储的数据
- .index:对应.log文件的索引信息
1 | 分区名称 = Topic名称 + 分区编号 |
3. Kafka的工作原理
3.1 Kafka的写入过程
- step1:生产者生产每一条数据,将数据放入一个batch批次中,如果batch满了或者达到一定的时间,提交写入请求
- step2:Kafka根据分区规则将数据写入分区,请求ZK获取对应的元数据,将请求提交给leader副本所在的Broker
- 元数据存储:Zookeeper中
- step3:先写入这台Broker的PageCache中
- Kafka也用了内存机制来实现数据的快速的读写:不同于Hbase的内存设计
- Hbase:JVM堆内存
- 所有Java程序都是使用JVM堆内存来实现数据管理
- 缺点:GC:从内存中清理掉不再需要的数据,导致GC停顿,影响性能,如果HRegionServer故障,JVM堆内存中的数据就丢失了,只能通过HLog恢复,性能比较差
- Kafka:操作系统Page Cache,选用了操作系统自带的缓存区域:PageCache(页缓存)
- 由操作系统来管理所有内存,即使Kafka Broker故障,数据依旧存在PageCache中
- step4:操作系统的后台的自动将页缓存中的数据SYNC同步到磁盘文件中:最新的Segment的.log中
- 顺序写磁盘:不断将每一条数据追加到.log文件中
- step5:其他的Follower到Leader中同步数据
3.2 为什么Kafka写入速度很快?
利用 Partition 实现并行处理
顺序写磁盘:Kafka 中每个分区是一个有序的,不可变的消息序列,新的消息不断追加到 partition 的末尾,这个就是顺序写。
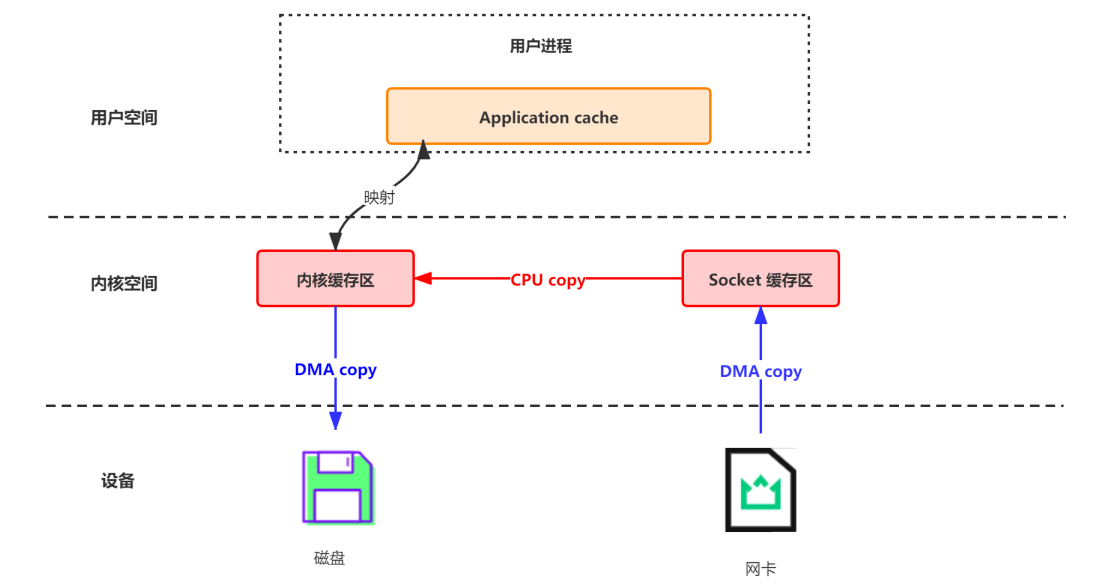
即便是顺序写入硬盘,硬盘的访问速度还是不可能追上内存。所以Kafka的数据并不是实时的写入硬盘 ,它充分利用了现代操作系统分页存储来利用内存提高I/O效率。
Memory Mapped Files:简称 mmap,也有叫 MMFile 的,使用 mmap 的目的是将内核中读缓冲区(read buffer)的地址与用户空间的缓冲区(user buffer)进行映射。从而实现内核缓冲区与应用程序内存的共享,省去了将数据从内核读缓冲区(read buffer)拷贝到用户缓冲区(user buffer)的过程。它的工作原理是直接利用操作系统的 Page 来实现文件到物理内存的直接映射。完成映射之后你对物理内存的操作会被同步到硬盘上。使用这种方式可以获取很大的 I/O 提升,省去了用户空间到内核空间复制的开销,也就是节省了CPU的开销。
传统的网络数据持久化到磁盘
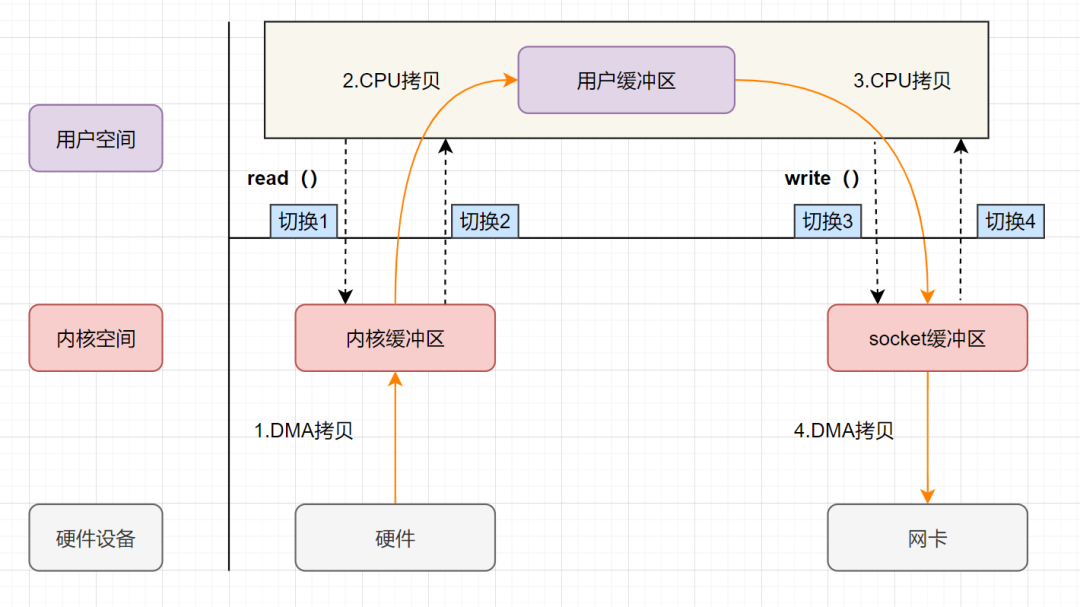
DMA(Direct Memory Access):直接存储器访问。DMA 是一种无需 CPU 的参与,让外设和系统内存之间进行双向数据传输的硬件机制。使用 DMA 可以使系统 CPU 从实际的 I/O 数据传输过程中摆脱出来,从而大大提高系统的吞吐率。
- 首先通过 DMA copy 将网络数据拷贝到内核态 Socket Buffer
- 然后应用程序将内核态 Buffer 数据读入用户态(CPU copy)
- 接着用户程序将用户态 Buffer 再拷贝到内核态(CPU copy)
- 最后通过 DMA copy 将数据拷贝到磁盘文件
- 如图:
3.3 Kafka的读取过程
- step1:消费者根据Topic、Partition、Offset提交给Kafka请求读取数据
- step2:Kafka根据元数据信息,找到对应的这个分区对应的Leader副本
- step3:请求Leader副本所在的Broker,先读PageCache,通过零拷贝机制【Zero Copy】读取PageCache
- step4:如果PageCache中没有,读取Segment文件段,先根据offset找到要读取的那个Segment
- step5:将.log文件对应的.index文件加载到内存中,根据.index中索引的信息找到Offset在.log文件中的最近位置,最近位置是指index中记录的稀疏索引【不是每一条数据都有索引】
- step6:读取.log,根据索引读取对应Offset的数据
3.4 为什么Kafka读取数据很快?
Linux 2.4+ 内核通过 sendfile 系统调用,提供了零拷贝。数据通过 DMA 拷贝到内核态 Buffer 后,直接通过 DMA 拷贝到 NIC Buffer,无需 CPU 拷贝。这也是零拷贝这一说法的来源。除了减少数据拷贝外,因为整个读文件 - 网络发送由一个 sendfile 调用完成,整个过程只有两次上下文切换,因此大大提高了性能。
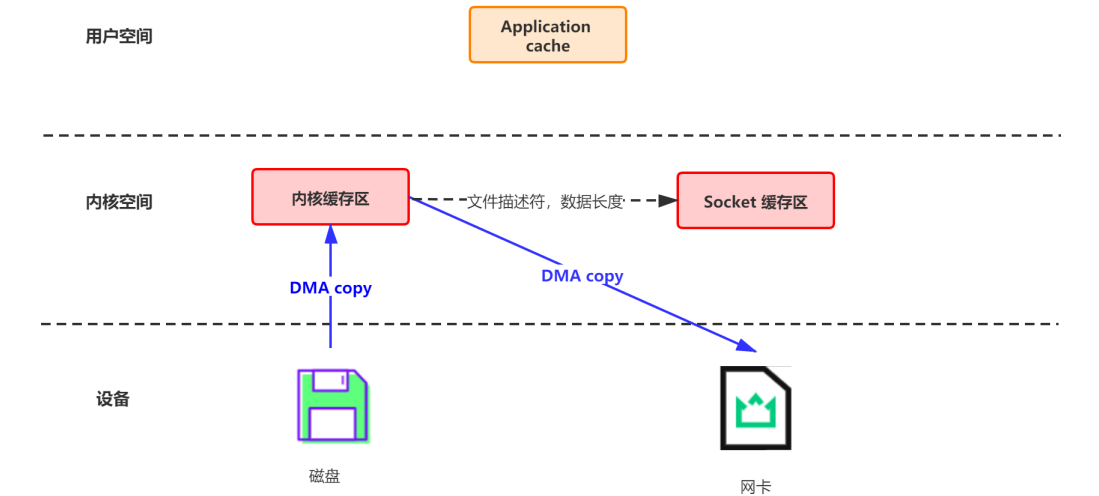
- 优先基于PageCache内存的读取,使用零拷贝机制
- 按照Offset有序读取每一条
- 构建Segment文件段
- 构建index索引
3.5 Kafka的存储中index的索引设计
常见的索类型:
- 全量索引:每一条数据,都对应一条索引
- 稀疏索引:部分数据有索引,有一部分数据是没有索引的,Kafka采用的是这种索引
- 优点:减少了索引存储的数据量 / 加快索引的检索效率**
- 什么时候生成一条索引?:
log.index.interval.bytes=4096,即.log文件每增加4096字节,在.index中增加一条索引
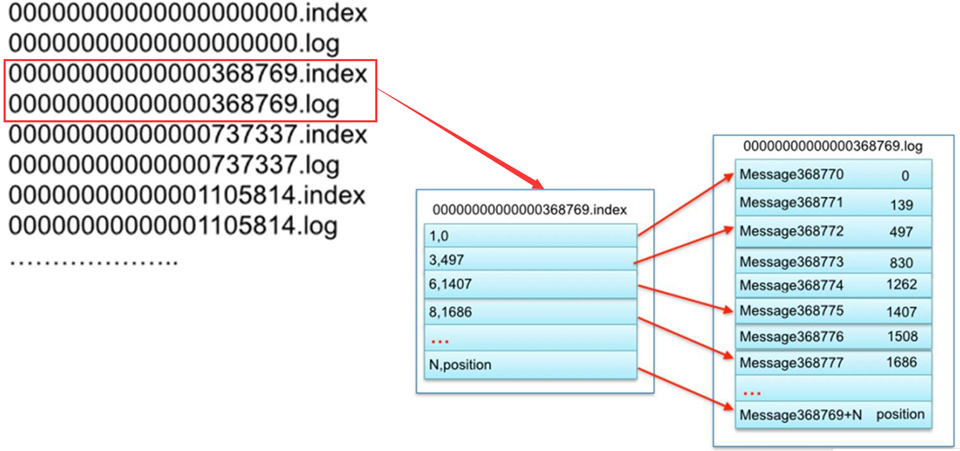
索引内容:
- 第一列:这条数据在这个文件中的位置
- 第二列:这条数据在文件中的物理偏移量
1 | 是这个文件中的第几条,数据在这个文件中的物理位置 |
检索数据流程:
- step1:先根据offset计算这条offset是这个文件中的第几条
- step2:读取.index索引,根据二分检索,从索引中找到离这条数据最近偏小的位置
- step3:读取.log文件从最近位置读取到要查找的数据
检索数据举例:
需求:查找offset = 368772
step1:计算是文件中的第几条
368772 - 368769 = 3 + 1 = 4,是这个文件中的第四条数据Topic: bigdata01 PartitionCount: 3 ReplicationFactor: 2 Configs: segment.bytes=1073741824 Topic: bigdata01 Partition: 0 Leader: 2 Replicas: 1,2 Isr: 2,1 Topic: bigdata01 Partition: 1 Leader: 0 Replicas: 0,1 Isr: 1,0 Topic: bigdata01 Partition: 2 Leader: 2 Replicas: 2,0 Isr: 2,01
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2. step2:读取.index索引,找到最近位置 【3,497】
3. step3:读取.log,从497位置向后读取一条数据,得到offset = 368772的数据
**为什么不直接将offset作为索引的第一列?**
- 因为Offset越来越大,导致索引存储越来越大,空间占用越多,检索索引比较就越麻烦
### 3.6 Kafka数据清理规则
- Kafka用于实现实时消息队列的数据缓存,不需要永久性的存储数据,如何将过期数据进行清理?
- delete方案:根据时间定期的清理过期的Segment文件,默认为7天
### 3.7 Kafka的分区副本概念:AR、ISR、OSR1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
- 分区副本机制:每个kafka中分区都可以构建多个副本,相同分区的副本存储在不同的节点上
- 为了保证安全和写的性能:划分了副本角色
- leader副本:对外提供读写数据
- follower副本:与Leader同步数据,如果leader故障,选举一个新的leader
- AR:All - Replicas
- 所有副本:指的是一个分区在所有节点上的副本
- **ISR**:In - Sync - Replicas
- **可用副本:Leader与所有正在与Leader同步的Follower副本**
- OSR:Out - Sync - Replicas
- 不可用副本:与Leader副本的同步差距很大,成为一个OSR列表的不可用副本
- 原因:网路故障等外部环境因素,某个副本与Leader副本的数据差异性很大
- 判断是否是一个OSR副本?
- 按照时间来判断
- ```sh
replica.lag.time.max.ms = 10000 #可用副本的同步超时时间
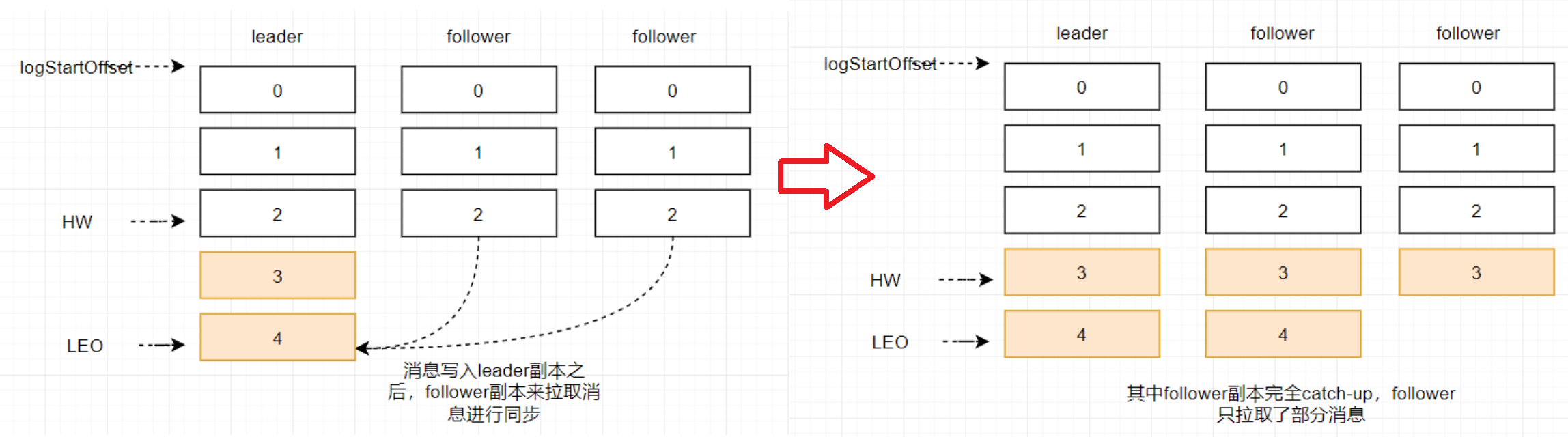
3.8 Kafka数据同步概念:HW、LEO
- HW:所有副本都同步的位置,消费者可以消费到的位置
- LEO:leader当前最新的位置
4. Kafka Questions
4.1 请简述Kafka生产数据时如何保证生产数据不丢失?
acks:返回的确认,当接收方收到数据以后,就会返回一个确认的消息
生产者向Kafka生产数据,根据配置要求Kafka返回ACK
ack=0:生产者不管Kafka有没有收到,直接发送下一条
- 优点:快
- 缺点:容易导致数据丢失,概率比较高
ack=1:生产者将数据发送给Kafka,Kafka等待这个分区leader副本写入成功,返回ack确认,生产者发送下一条
- 优点:性能和安全上做了平衡
- 缺点:依旧存在数据丢失的概率,但是概率比较小
ack=all/-1:生产者将数据发送给Kafka,Kafka等待这个分区所有副本全部写入,返回ack确认,生产者发送下一条
- 优点:数据安全
- 缺点:慢
- 方案:搭配min.insync.replicas来使用
- min.insync.replicas:表示最少同步几个副本就可以返回ack
如果Kafka没有返回ACK怎么办?
- 生产者会等待Kafka返回ACK,有一个超时时间,如果Kafka在规定时间内没有返回ACK,说明数据丢失了
- 生产者有重试机制,重新发送这条数据给Kafka
- 问题:如果ack在中途丢失,Kafkahi导致数据重复问题,怎么解决?
4.2 常见的生产数据分区规则?
MapReduce:Hash分区
- 优点:相同的Key会进入同一个分区
- 缺点:数据倾斜的问题,如果所有Key的Hash取余的结果一样,导致数据分配不均衡的问题
Hbase:范围分区
轮询分区(kafka2.x之前,当不指定分区策略时,采用此分区规则)
- 优点:数据分配更加均衡
- 缺点:相同Key的数据进入不同的分区中
随机分区
槽位分区
4.3 Kafka生产数据的分区规则?
重点理解:为什么生产数据的方式不同,分区的规则就不一样?
2
3
ProducerRecord(Topic,Key,Value)//指定了key
ProducerRecord(Topic,Partition,Key,Value)//指定了Partiotion、key
流程:
先判断是否指定了分区
如果指定了分区:

如果没指定分区:

默认调用的是DefaultPartitioner分区器中partition这个方法:

再判断是否给定了Key:
- 如果指定了key,按照Key的Hash取余分区的个数,来写入对应的分区
- 如果没有指定Key:
- 2.X之前采用轮询分区,则将过来的数据每条依次与partition创建连接欸,并均匀的发送到每个partition中
- 优点:数据分配相对均衡
- 缺点:性能非常差
- 2.X之后,采用粘性分区
- 让数据尽量的更加均衡,实现少批次多数据
- 第一次:将所有数据随机选择一个分区,全部写入这个分区中,将这次的分区编号放入缓存中
- 第二次开始根据缓存中是否有上一次的编号,有:直接使用上一次的编号,如果没有:重新随机选择一个
- 2.X之前采用轮询分区,则将过来的数据每条依次与partition创建连接欸,并均匀的发送到每个partition中
4.4 如何自定义分区策略
通过自定义开发分区器
- step1:构建一个类实现Partitioner接口
- step2:实现partition方法:定义分区逻辑
- step3:加载指定分区器即可
1 | package bigdata.itcast.cn.kafka.partition; |
使用分区器:
1 | //指定分区器的类 |
4.5 消费者消费过程及问题
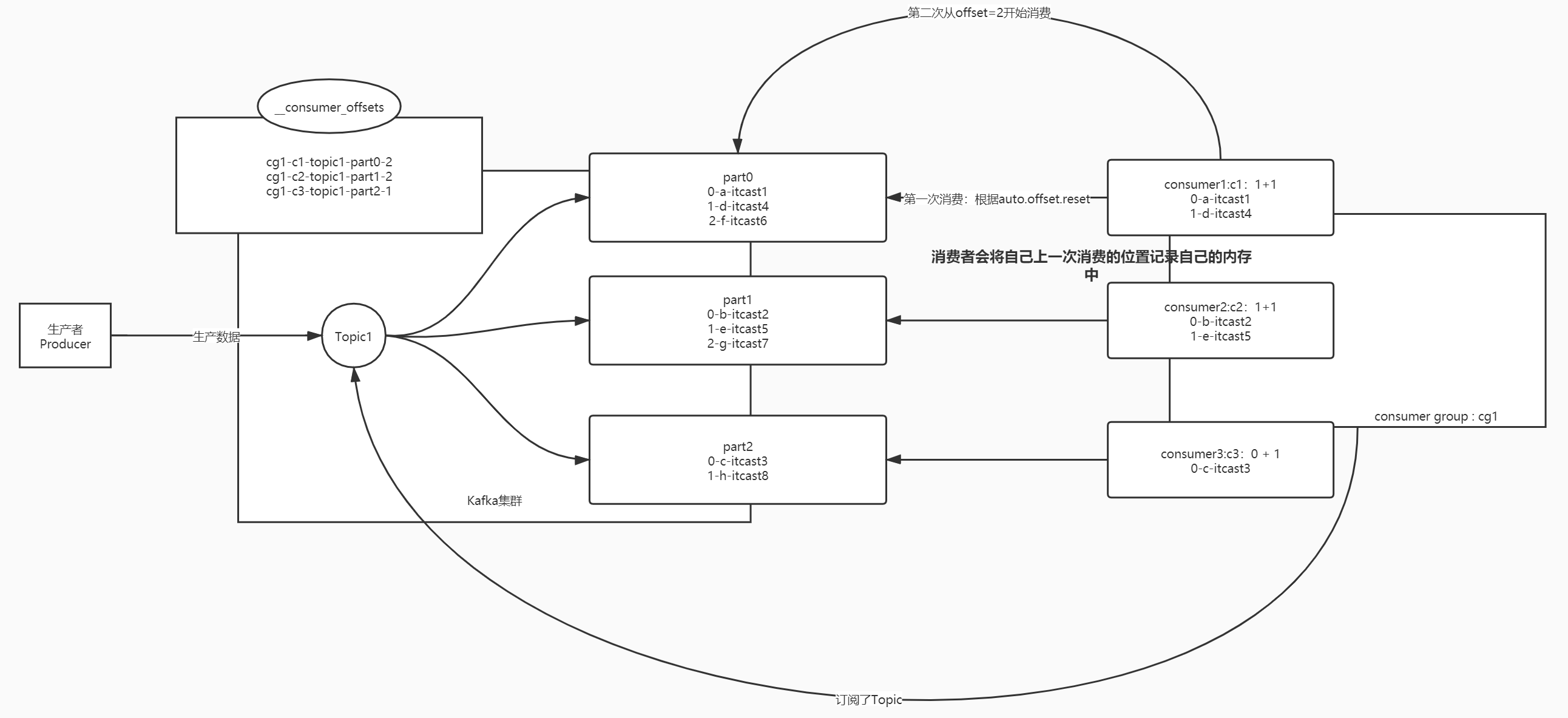
- 消费者的数据消费规则
- 消费者消费Kafka中的Topic根据Offset进行消费,每次从上一次的位置继续消费
- 第一次消费规则:由属性决定
auto.offset.reset- latest:默认的值,从Topic每个分区的最新的位置开始消费
- earliest:从最早的位置开始消费,每个分区的offset为0开始消费
- 第二次消费开始:根据上一次消费的Offset位置+1继续进行消费
- 消费者如何知道上一次消费的位置是什么?
- 每个消费者都将自己上一次消费的offset记录自己的内存中
- 如果因为网络资源原因,消费者故障了,重启消费者,原来内存中offset就没有了,消费者消费的时候怎么知道上一次消费的位置?
4.6 Kafka Offset偏移量管理
Kafka将每个消费者消费的位置主动记录在一个Topic中:__consumer_offsets
如果下次消费者没有给定请求offset,kafka就根据自己记录的offset来提供消费的位置
offset的提交规则:
根据时间自动提交
props.setProperty("enable.auto.commit", "true");//是否自动提交offset props.setProperty("auto.commit.interval.ms", "1000");//提交的间隔时间1
2
3
4
5
6
7
8
9
10
11
12
13
14
### 4.7 自动提交Offset的问题
- 自动提交的规则
- 根据时间周期来提交下一次要消费的offset
- ```java
props.setProperty("enable.auto.commit", "true");//是否自动提交offset
props.setProperty("auto.commit.interval.ms", "1000");//提交的间隔时间
数据丢失的情况
- 如果刚消费,还没处理,就达到提交周期,记录了当前 的offset
- 最后处理失败,需要重启,重新消费处理
- Kafka中已经记录消费过了,从上次消费的后面进行消费,出现部分数据丢失
数据重复的情况
- 如果消费并处理成功,但是没有提交offset,程序故障
- 重启以后,kafka中记录的还是之前的offset,重新又消费一遍
- 数据出现重复问题
结论:消费是否成功,是根据处理的结果来决定的,如果蛋蛋依赖kafka自动提交offset是根据时间周期来决定的,不可靠,所以:根据处理的结果来决定是否提交offse,要使用手动的方式来提交offset。
- 如果消费并处理成功:提交offset
- 如果消费处理失败:不提交offset
4.8 实现手动提交Topic的Offset
关闭自动提交
1
2props.setProperty("enable.auto.commit", "false");//是否自动提交offset
//props.setProperty("auto.commit.interval.ms", "1000");//提交的间隔时间根据处理的结果来实现手动提交Offset,如果成功以后,再提交
1
2//相应的逻辑处理完成后,手动提交offset
consumer.commitSync();
4.9 手动提交Offset的问题
- Offset是什么级别的?
- Offset是分区级别,每个分区单独管理一套offset
- 手动提交Topic Offset的过程中会出现数据重复?
- 如果一个消费者,消费一个Topic,Topic有三个分区,当part0和part1都处理成功,当处理part2时候,程序故障
- 此时如果程序使用的是
consumer.commitSync();来提交offset的话,就会出现问题了,因为刚才在三个分区还没有全部处理完,还没有触发consumer.commitSync();的执行。但是分区1和2的数据已经成功消费处理了。 - 下次重新启动consumer的时候就会导致0和1分区的数据重复消费
- 原因:Offset是分区级别的,提交offset是按照整个Topic级别来提交的
- 解决:
- 提交offset的时候,按照分区来提交
- 消费成功一个分区,就提交一个分区的offset
4.10 手动提交分区Offset的实现
- step1:消费每个分区的数据
- step2:处理输出每个分区的数据
- step3:手动提交每个分区的Offset
1 | //取出每个Partition的数据 |
- 注意:工作中:一般不将Offset由Kafka存储,一般自己存储
- 如果处理成功:将offset存储在MySQL或者Redis中
- 如果重启程序:从MySQL或者Redis读取上一次的offset来实现
4.11 指定消费Topic分区的数据
- step1:构建Topic分区对象
- step2:指定消费Topic的分区
- step3:输出消费结果
1 | //构建分区对象 |
4.12 消费的基本规则
- 一个分区只能由消费者组中的一个消费者来消费,不同消费者组之间互不影响,但是拿到的是同一份数据
- 一个消费者组下面的一个消费者可以消费多个分区的数据,但是多个消费者不能同时消费一个分区,因为要保证一个消费者组得到的是一份数据,不然消费到的数据会重复,倘若同一消费者组的多个消费者同时读取同一个分区,无论是kafka维护偏移量还是客户端维护偏移量,都会造成数据的不一致,因为各个消费者对数据的消费处理速度是不同的。
- 一般情况下:消费者数量⩾分区数量,或者消费者的数量是分区数量的倍数
4.13 kafka的消费分配策略
RangeAssignor(范围分配策略)
Kafka中默认的分配规则
每个消费者消费一定范围的分区,尽量的实现将分区均分给不同的消费者,如果不能均分,优先将分区分配给编号小的消费者
1
2
3
4
5
6
7
8
96个分区:part0 ~ part5
2个消费者时:
C1:part0 ~ part2
C2:part3 ~ part5
4个消费者时:
C1:part0 part1
C2:part2 part3
C3:part4
C4:part5范围分配优点:如果Topic的个数比较少,分配会相对比较均衡
范围分配缺点:如果Topic的个数比较多,而且不能均分,导致负载不均衡问题
应用:Topic个数少或者每个Topic都均衡的场景
RoundRobinAssignor(轮询分配策略)
- 按照Topic的分区编号,轮询分配给每个消费者
- 轮询分配的优点:如果有多个消费者,消费的Topic都是一样的,实现将所有Topic的所有分区轮询分配给所有消费者,尽量的实现负载的均衡
大多数的场景都是这种场景 - 轮询分配的缺点:遇到消费者订阅的Topic是不一致的,不同的消费者订阅了不同Topic,只能基于订阅的消费者进行轮询分配,导致整体消费者负载不均衡的
- 应用场景:所有消费者都订阅共同的Topic,能实现让所有Topic的分区轮询分配所有的消费者
StickyAssignor(黏性分配策略)
- 轮询分配的规则
- 类似于轮询分配,尽量的将分区均衡的分配给消费者
- 黏性分配的特点
- 相对的保证的分配的均衡
- 如果某个消费者故障,要进行负载均衡的时候,会尽量的避免网络传输
- 尽量保证原来的消费的分区不变,将多出来分区均衡给剩余的消费者
- 轮询分配的规则
4.14 kafka为什么快
- partition 并行处理
- 顺序读写磁盘,充分利用磁盘特性
- 利用了现代操作系统分页存储 Page Cache 来利用内存提高 I/O 效率
- 采用了零拷贝技术
- Producer 生产的数据持久化到 broker,采用 mmap 文件映射,实现顺序的快速写入
- Customer 从 broker 读取数据,采用 sendfile,将磁盘文件读到 OS 内核缓冲区后,转到 NIO buffer进行网络发送,减少 CPU 消耗
4.15 消息队列的一次性语义
- at-most-once:至多一次
- 会出现数据丢失的问题
- at-least-once:至少一次
- 会出现数据重复的问题
- exactly-once:有且仅有一次
- 只消费处理成功一次
- 所有消息队列的目标
4.16 Kafka如何保证生产不丢失
- ACK + 重试机制
- step1:生产数据时等待Kafka的ack
- step2:返回ack再生产下一条
4.17 Kafka如何保证生产不重复
- Kafka通过幂等性机制在数据中增加数据id,每条数据的数据id都不一致
- Kafka会判断每次要写入的id是否比上一次的id多1,如果多1,就写入,不多1,就直接返回ack
4.18 Kafka保证消费一次性语义
通过自己手动管理存储Offset来实现
- step1:第一次消费根据属性进行消费
- step2:消费分区数据,处理分区数据
- step3:处理成功:将处理成功的分区的Offset进行额外的存储
- Kafka:默认存储__consumer_offsets
- 外部:MySQL、Redis、Zookeeper
- step4:如果消费者故障,可以从外部存储读取上一次消费的offset向Kafka进行请求
4.19 消息队列有什么好处?
- 实现解耦,将高耦合转换为低耦合
- 通过异步并发,提高性能,并实现最终一致性
4.20 Kafka中消费者与消费者组的关系是什么?
- 消费者组负责订阅Topic,消费者负责消费Topic分区的数据
- 消费者组中可以包含多个消费者,多个消费者共同消费数据,增加消费并行度,提高消费性能
- 消费者组的id由开发者指定,消费者的id由Kafka自动分配
4.21 Kafka中Topic和Partition是什么,如何保证Partition数据安全?
Topic:逻辑上实现数据存储的分类,类似于数据库中的表概念
Partition:Topic中用于实现分布式存储的物理单元,一个Topic可以有多个分区
- 每个分区可以存储在不同的节点,实现分布式存储
保证数据安全通过副本机制:Kafka中每个分区可以构建多个副本【副本个数 <= 机器的个数】
将一个分区的多个副本分为两种角色
leader副本:负责对外提供读写请求
follower副本:负责与leader同步数据,如果leader故障,follower要重新选举一个成为leader
选举:由Kafka Crontroller来决定谁是leader
4.22 一个消费者组中有多个消费者,消费多个Topic多个分区,分区分配给消费者的分配规则有哪些?
- 分配场景
- 第一次消费:将分区分配给消费者
- 负载均衡实现:在消费过程中,如果有部分消费者故障或者增加了新的消费
- 基本规则
- 一个分区只能被一个消费者所消费
- 一个消费者可以消费多个分区
- 分配规则
- 范围分配
- 规则:每个消费者消费一定范围的分区,尽量均分,如果不能均分,优先分配给标号小的
- 应用:消费比较少的Topic,或者多个Topic都能均分
- 轮询分配
- 规则:按照所有分区的编号进行顺序轮询分配
- 应用:所有消费者消费的Topic都是一致的,能实现将所有分区轮询分配给所有消费者
- 黏性分配
- 规则:尽量保证分配的均衡,尽量避免网络的IO,如果出现故障,保证 每个消费者依旧消费原来的分区,将多出来的分区均分给剩下的消费者
- 应用:建议使用分配规则
- 范围分配
4.23 Kafka如何保证消费者消费数据不重复不丢失?
- Kafka消费者通过Offset实现数据消费,只要保证各种场景下能正常实现Offset的记录即可
- 保证消费数据不重复需要每次消费处理完成以后,将Offset存储在外部存储中,例如MySQL、Zookeeper、Redis中
- 保证以消费分区、处理分区、记录分区的offset的顺序实现消费处理
- 如果故障重启,只要从外部系统中读取上一次的Offset继续消费即可
4.24 Kafka常用的API
生产者API:生产数据到Kafka
- step1:构建ProducerRecord对象
- step2:调用KafkaProducer的send方法将数据写入Kafka
消费者API:构建KafkaConsumer
- step1:构建集群配置对象
- step2:构建Kafka Consumer对象
1 | //todo:1-构建连接,消费者对象 |
消费者API:消费Topic数据
- step1:消费者订阅Topic
- step2:调用poll方法从Kafka中拉取数据,获取返回值
- step3:从返回值中输出:Topic、Partition、Offset、Key、Value
1 | //订阅Topic |
4.25 Kafka常用的配置参数
参考文档: