你必须Get的开源CDC技术[Debezium]

1. Debezium是什么
1.1 背景
Debezium是RedHat开源的并依赖于Apache Kafka Connect的源连接器(source端),通过剖析数据库中binlog日志,捕获数据,拷贝到kafka中,实现数据的实时抽取。
1.2 官网介绍
Debezium是一个用于变更数据采集的开源分布式平台。配置采集任务并指定你要捕获的数据库,然后启动任务,就可以开始响应其他应用程序提交给你的数据库的所有插入、更新和删除。Debezium是持久和快速的,所以你的采集任务可以快速响应,不会错过任何一个并更的event,即使任务出错。
1.3 架构
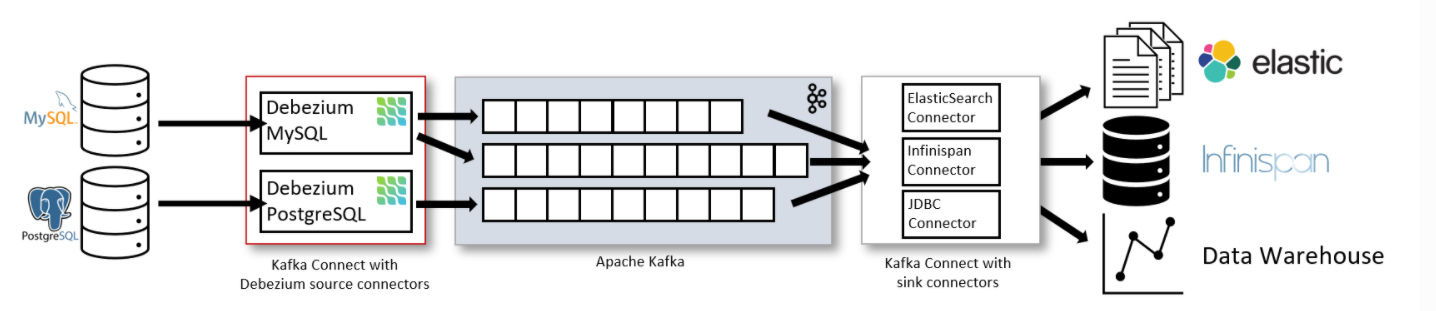
上图主要呈现了三点:
- Kafka不仅在整个链路中充当了解耦的作用,同时也是CDC数据的载体
- 通过Debezium这款Kafka-Source连接器可以将采集到的数据发送到Kafka消息队列
- 发送到kafka后,也可以使用Kafka Sink Connector将Kafka中的数据发送到其他存储系统(例如Es/MySQL等)
1.4 部署前提
- Zookeeper
- 分布式协调服务,Kafka集群的运行需要依赖Zookeeper来实现(Kafka集群选主)
- 尽管Kafka在逐渐的摆脱Zookeeper这种依赖关系,例如现在的Offset信息存储在自己的topic中
- Kafka
- 消息队列,
- Kafka-Connect (Debezium依赖于Kafka-Connect,说)
- Kafka2.0.0以后,已经自带Kafka-Connect
- Kafka-Connect是分布式服务,支持distributed和standalone两种模式
- Debezium相当于是Kafka-Source-Connector的实现,是Kafka的数据源,负责将数据传送到Kafka集群
- Confluen Avro Regisry Schema
- 不是必须安装,如果传输Avro格式数据,需要安装
- Avro格式的数据是一种压缩的byte格式数据,在传输过程中只传输数据本身,不需要像JSON那样需要携带数据的schema,只不过Avro将schema存储到Schema注册中心,这样大大的节省了数据量开销。
实践Tips:
- 如果你使用的是原生的Kafka(2.0.0之后),
2.0.0之后kafka虽然内置了Kafka Connect,但是想要在Kafka中使用Avro格式来传输数据,需要额外安装Confluen Avro Regisry Schema才行- 如果你使用的是Confluent Kafka,就可以开箱即用
Debezium,因为Confluent Kafka已经帮你把这些都做好了,你只需指定plugin.path路径,并将你要安装的debezium解压进去,重启connect服务即可
1.5 安装Debezium
安装Debezium在这里就不罗嗦了,因为官方说的比我都清楚,而且每个connector的安装都是大同小异,这里是官方的Debezium MySQL connector的安装步骤:
Debezium MySQL connector的安装指南 【传送门】
2. Debezium目前的状况
2.1 Debezium目前支持的数据库
| 1.4 | |
|---|---|
| Java | 8+ |
| Kafka Connect | 1.x, 2.x |
| MySQL | Database: 5.7, 8.0.x JDBC Driver: 8.0.19 |
| MongoDB | Database: 3.2, 3.4, 3.6, 4.0, 4.2 Driver: 3.12.3 |
| PostgreSQL | Database: 9.6, 10, 11, 12 JDBC Driver: 42.2.12 |
| Oracle | Database: 11g, 12c JDBC Driver: 12.2.0.1 |
| SQL Server | Database: 2017, 2019 JDBC Driver: 7.2.2.jre8 |
| Cassandra | Database: 3.11.4 Driver: 3.5.0 |
| Db2 | Database: 11.5 JDBC Driver: 11.5.0.0 |
| Vitess | Database: 8.0.x JDBC Driver: 7.0.0 |
2.2 Debezium支持的数据传输格式
目前Debezium采集到的数据支持以JSON或者Apache Avro的格式发往Kafka,用户可以在配置文件中指定
这里以Confluent Kafka的配置问件connect-distributed.properties为例:
1 | #发送到kafka的集群地址 |
3. Debezium与Flink
3.1 传统的Debezium+Kafka架构
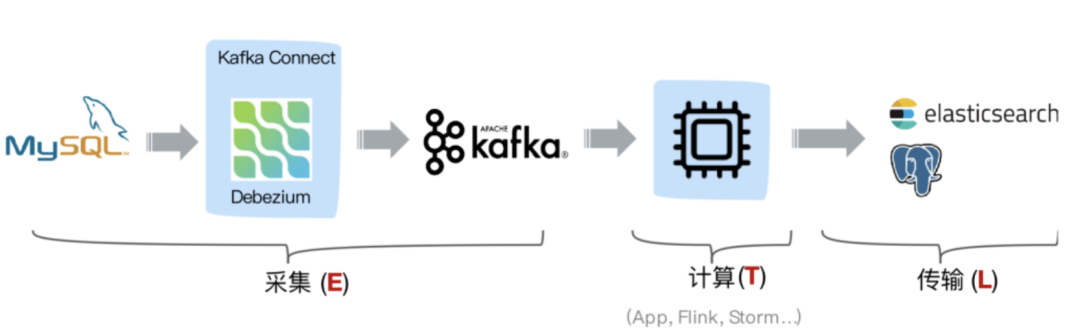
这种方案中利用 Kafka 消息队列做解耦,Change Log 可供任何其他业务系统使用,消费端可采用 Kafka Sink Connector 或者自定义消费程序,但是由于原生 Debezium 中的 Producer 端未采用幂等特性,因此消息可能存在重复。
- 中间计算层使用Flink可以灵活的接收来自Kafka中不同格式的数据进行计算最后Sink到不同的地方
3.2 Debezium与Flink SQL
3.2.1 利用Flink SQL接入kafka中debezium-json格式数据
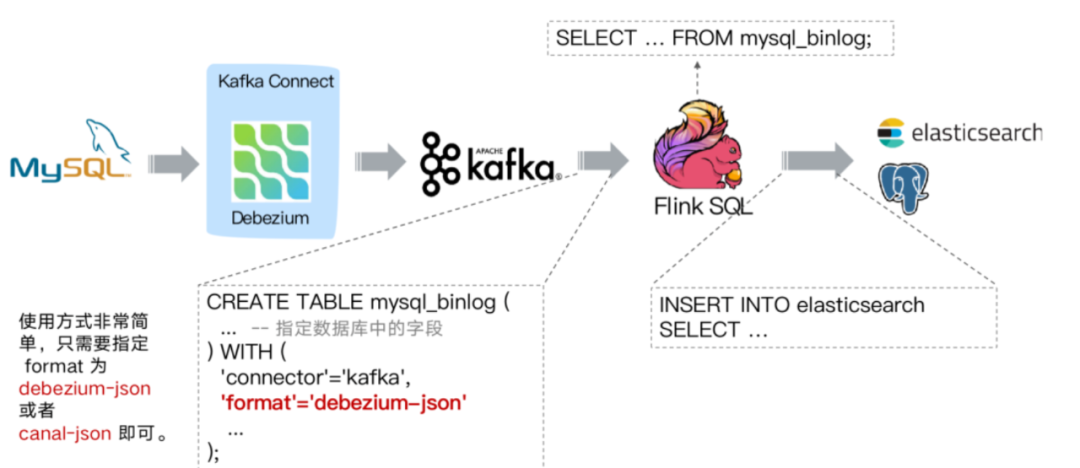
与传统方案的区别就是,通过Flink SQL创建 Kafka 表,指定 format 格式为 debezium-json,然后通过 Flink 进行计算后或者直接插入到其他外部数据存储系统。方案二和方案一类似,组件多维护繁杂,而前述我们知道 Flink 1.11 中 CDC Connectors 内置了 Debezium 引擎,可以替换 Debezium+Kafka 方案,因此有了更简化的方案(3.2.2)。
3.2.2 直接使用Flink SQL进行数据采集
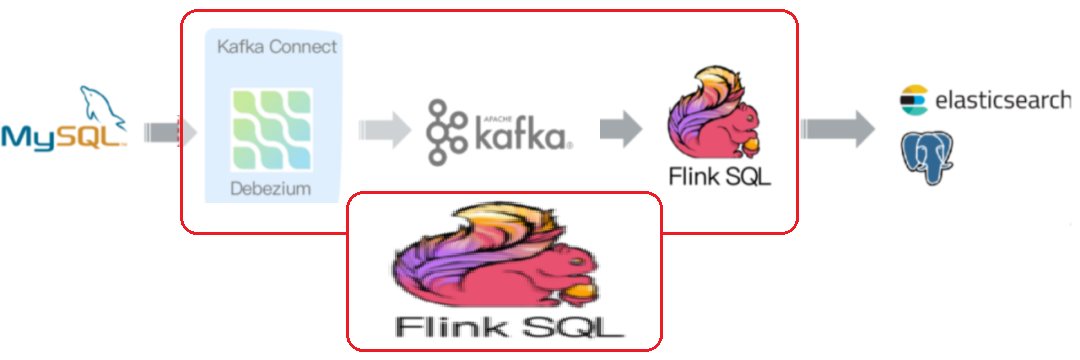
从官方的描述中,通过 Flink CDC connectors 替换 Debezium+Kafka 的数据采集模块,实现 Flink SQL 采集+计算+传输(ETL)一体化,优点很多:
- 开箱即用,简单易上手
- 减少维护的组件,简化实时链路,减轻部署成本
- 减小端到端延迟
- Flink 自身支持 Exactly Once 的读取和计算
- 数据不落地,减少存储成本
- 支持全量和增量流式读取
- binlog 采集位点可回溯
4. Debezium实践特性
4.1 MySQL
- 支持增量、全量数据的采集
- 高可用,某个节点挂机,会重新将采集任务调度到其他节点
- 采集粒度支持
库/表/列级别 - 通过GTID-Mode支持事务性采集数据
- GTID(Global Unique Identifer)全局唯一标记,GTID可以保证在主从复制的时候做到一致性,意味着debezium可以保证采集到的数据做到事务一致性
- Tips:Flink SQL可以通过checkpoint机制来实现exactly once,CheckpointedFuntion中利用binlog-id来实现
提示:我的另一篇会专门以Debezium-Mysql为例来全面介绍任务的配置、发布和遇到的问题
4.2 SQLServer
- 支持增量、全量数据的采集
- 高可用,某个节点挂机,会重新将采集任务调度到其他节点
- 采集粒度支持
库/表/列级别 - 采集任务的语义可以做到at-least-once
- SQLServer的bin-log记录到一张系统表上
4.3 Oracle(孵化中)
- 采集方式支持两种
- LogMiner
- XStream(需要购买Oracle Golden Gate的License版权)
- 支持全量的数据采集
- 采集粒度支持
库/表级别
5. Debezium目前存在的问题
- Kafka集群地址不可在任务上自由配置,在部署时候就已经确定
- 数据采集格式不可在任务上自由配置,在部署时候就已经确定
- Oracle支持的不够稳定、容错支持的不够好,Oracle服务器重启,采集任务无法正常运行,不能唤起