深入理解Flink_end-to-end_exactly-once语义
上一篇文章所述的Exactly-Once语义是针对Flink系统内部而言的.
那么Flink和外部系统(如Kafka)之间的消息传递如何做到exactly once呢?
1. Flink内部仅实现exactly once问题所在:
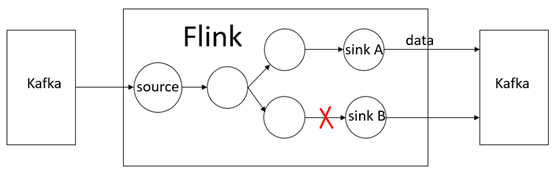
如上图,当sink A已经往Kafka写入了数据,而sink B fail.
根据Flink的exactly once保证,系统会回滚到最近的checkpoint,
但是sink A已经把数据写入到kafka了.
Flink无法回滚kafka的state.因此,kafka将在之后再次接收到一份同样的来自sink A的数据,
这样的message delivery便成为了at least once
2. 解决方案-Two phase commit
Flink采用Two phase commit来解决这个问题.
- Phase 1: Pre-commit
- Flink的JobManager向source注入checkpoint barrier以开启这次snapshot.
- barrier从source流向sink.
- 每个进行snapshot的算子成功snapshot后,都会向JobManager发送ACK.
- 当sink完成snapshot后, 向JobManager发送ACK的同时向kafka进行pre-commit.
- Phase 2: Commit
- 当JobManager接收到所有算子的ACK后,就会通知所有的算子这次checkpoint已经完成.
- Sink接收到这个通知后, 就向kafka进行commit,正式把数据写入到kafka
不同阶段Fail over的recovery举措:
- 在pre-commit前fail over, 系统恢复到最近的checkponit
- 在pre-commit后,commit前fail over,系统恢复到刚完成pre-commit时的状态
3. Flink的two phase commit实现
抽象类TwoPhaseCommitSinkFunction
TwoPhaseCommitSinkFunction有4个方法:
beginTransaction()
开启事务.创建一个临时文件.后续把原要写入到外部系统的数据写入到这个临时文件
preCommit()
flush并close这个文件,之后便不再往其中写数据.同时开启一个新的事务供下个checkponit使用
commit()
把pre-committed的临时文件移动到指定目录
abort()
删除掉pre-committed的临时文件