在分布式系统中,为了让每个节点都能够感知到其他节点的事务执行状况,需要引入一个中心节点来统一处理所有节点的执行逻辑,这个中心节点叫做协调者(coordinator),被中心节点调度的其他业务节点叫做参与者(participant)。
接下来正式介绍2PC。顾名思义,2PC将分布式事务分成了两个阶段,两个阶段分别为提交请求(投票)和提交(执行)。协调者根据参与者的响应来决定是否需要真正地执行事务,具体流程如下。
1. 提交请求(投票)阶段
- 协调者向所有参与者发送prepare请求与事务内容,询问是否可以准备事务提交,并等待参与者的响应。
- 参与者执行事务中包含的操作,并记录undo日志(用于回滚)和redo日志(用于重放),但不真正提交。
- 参与者向协调者返回事务操作的执行结果,执行成功返回yes,否则返回no。
2. 提交(执行)阶段
分为成功与失败两种情况。
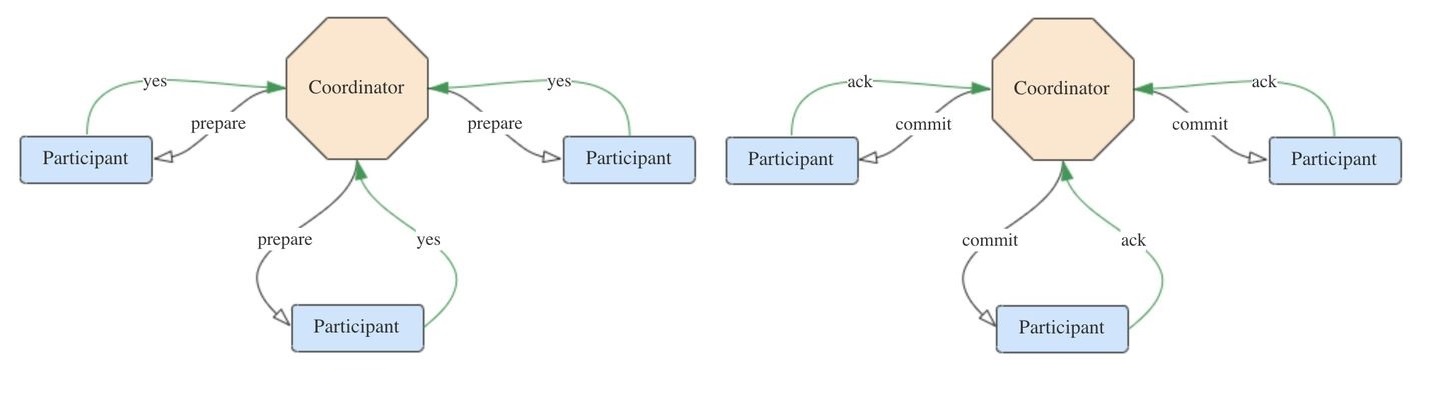
若所有参与者都返回yes,说明事务可以提交:
- 协调者向所有参与者发送commit请求。
- 参与者收到commit请求后,将事务真正地提交上去,并释放占用的事务资源,并向协调者返回ack。
- 协调者收到所有参与者的ack消息,事务成功完成。
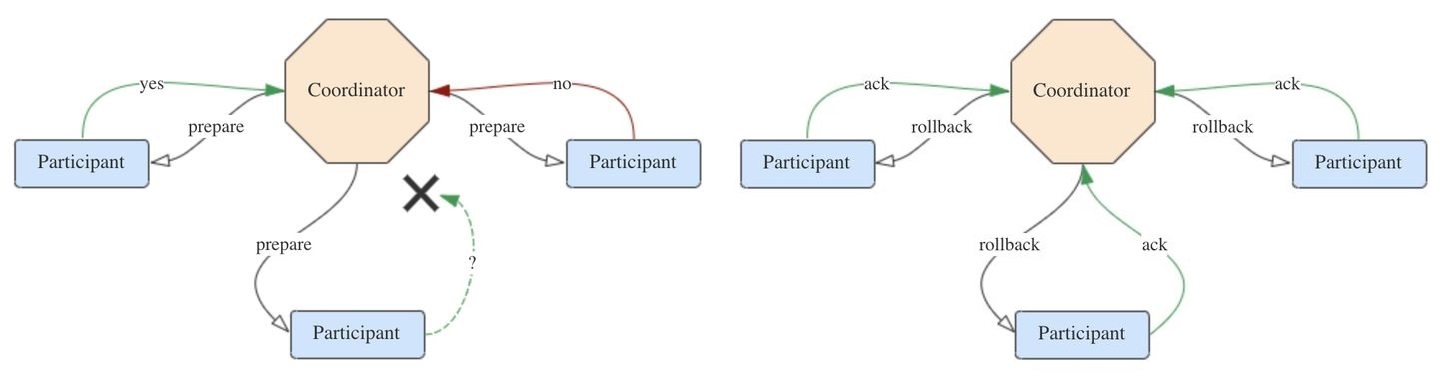
若有参与者返回no或者超时未返回,说明事务中断,需要回滚:
- 协调者向所有参与者发送rollback请求。
- 参与者收到rollback请求后,根据undo日志回滚到事务执行前的状态,释放占用的事务资源,并向协调者返回ack。
- 协调者收到所有参与者的ack消息,事务回滚完成。
下图分别示出这两种情况:
提交成功
提交失败
3. Flink基于2PC的事务性写入
Flink提供了基于2PC的SinkFunction,名为TwoPhaseCommitSinkFunction,帮助我们做了一些基础的工作。它的第一层类继承关系如下:

但是TwoPhaseCommitSinkFunction仍然留了以下四个抽象方法待子类来实现:
1
2
3
4
| protected abstract TXN beginTransaction() throws Exception;
protected abstract void preCommit(TXN transaction) throws Exception;
protected abstract void commit(TXN transaction);
protected abstract void abort(TXN transaction);
|
beginTransaction():开始一个事务,返回事务信息的句柄。
preCommit():预提交(即提交请求)阶段的逻辑。
commit():正式提交阶段的逻辑。
abort():取消事务。
下面以Flink与Kafka的集成来说明2PC的具体流程。注意这里的Kafka版本必须是0.11及以上,因为只有0.11+的版本才支持幂等producer以及事务性,从而2PC才有存在的意义。
3.1 开始事务
看下FlinkKafkaProducer011类实现的beginTransaction()方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| @Override
protected KafkaTransactionState beginTransaction() throws FlinkKafka011Exception {
switch (semantic) {
case EXACTLY_ONCE:
FlinkKafkaProducer<byte[], byte[]> producer = createTransactionalProducer();
producer.beginTransaction();
return new KafkaTransactionState(producer.getTransactionalId(), producer);
case AT_LEAST_ONCE:
case NONE:
final KafkaTransactionState currentTransaction = currentTransaction();
if (currentTransaction != null && currentTransaction.producer != null) {
return new KafkaTransactionState(currentTransaction.producer);
}
return new KafkaTransactionState(initNonTransactionalProducer(true));
default:
throw new UnsupportedOperationException("Not implemented semantic");
}
}
|
如果在Flink里面明确要求exactly once语义时,就会创建事务生产者并且启动事务。
3.2 预提交阶段
FlinkKafkaProducer011.preCommit()方法的实现很简单。其中的flush()方法实际上是代理了KafkaProducer.flush()方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| @Override
protected void preCommit(KafkaTransactionState transaction) throws FlinkKafka011Exception {
switch (semantic) {
case EXACTLY_ONCE:
case AT_LEAST_ONCE:
flush(transaction);
break;
case NONE:
break;
default:
throw new UnsupportedOperationException("Not implemented semantic");
}
checkErroneous();
}
|
那么preCommit()方法是在哪里使用的呢?答案是TwoPhaseCommitSinkFunction.snapshotState()方法。从前面的类图可以得知,TwoPhaseCommitSinkFunction也继承了CheckpointedFunction接口,所以2PC是与检查点机制一同发挥作用的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| @Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
checkState(currentTransactionHolder != null, "bug: no transaction object when performing state snapshot");
long checkpointId = context.getCheckpointId();
LOG.debug("{} - checkpoint {} triggered, flushing transaction '{}'", name(), context.getCheckpointId(), currentTransactionHolder);
preCommit(currentTransactionHolder.handle);
pendingCommitTransactions.put(checkpointId, currentTransactionHolder);
LOG.debug("{} - stored pending transactions {}", name(), pendingCommitTransactions);
currentTransactionHolder = beginTransactionInternal();
LOG.debug("{} - started new transaction '{}'", name(), currentTransactionHolder);
state.clear();
state.add(new State<>(
this.currentTransactionHolder,
new ArrayList<>(pendingCommitTransactions.values()),
userContext));
}
|
结合Flink检查点的原理,可以用下图来形象地表示预提交阶段的流程:
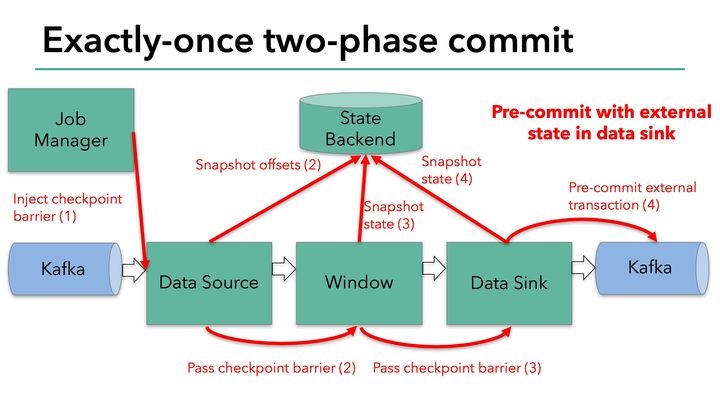
每当需要做checkpoint时,JobManager就在数据流中打入一个屏障(barrier),作为检查点的界限。屏障随着算子链向下游传递,每到达一个算子都会触发将状态快照写入状态后端(state BackEnd)的动作。当屏障到达Kafka sink后,触发preCommit(实际上是KafkaProducer.flush())方法刷写消息数据,但还未真正提交。接下来还是需要通过检查点来触发提交阶段。
3.3 提交阶段
FlinkKafkaProducer011.commit()方法实际上是代理了KafkaProducer.commitTransaction()方法,正式向Kafka提交事务。
1
2
3
4
5
6
7
8
9
10
| @Override
protected void commit(KafkaTransactionState transaction) {
if (transaction.isTransactional()) {
try {
transaction.producer.commitTransaction();
} finally {
recycleTransactionalProducer(transaction.producer);
}
}
}
|
该方法的调用点位于TwoPhaseCommitSinkFunction.notifyCheckpointComplete()方法中。顾名思义,当所有检查点都成功完成之后,会回调这个方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| @Override
public final void notifyCheckpointComplete(long checkpointId) throws Exception {
Iterator<Map.Entry<Long, TransactionHolder<TXN>>> pendingTransactionIterator = pendingCommitTransactions.entrySet().iterator();
checkState(pendingTransactionIterator.hasNext(), "checkpoint completed, but no transaction pending");
Throwable firstError = null;
while (pendingTransactionIterator.hasNext()) {
Map.Entry<Long, TransactionHolder<TXN>> entry = pendingTransactionIterator.next();
Long pendingTransactionCheckpointId = entry.getKey();
TransactionHolder<TXN> pendingTransaction = entry.getValue();
if (pendingTransactionCheckpointId > checkpointId) {
continue;
}
LOG.info("{} - checkpoint {} complete, committing transaction {} from checkpoint {}",
name(), checkpointId, pendingTransaction, pendingTransactionCheckpointId);
logWarningIfTimeoutAlmostReached(pendingTransaction);
try {
commit(pendingTransaction.handle);
} catch (Throwable t) {
if (firstError == null) {
firstError = t;
}
}
LOG.debug("{} - committed checkpoint transaction {}", name(), pendingTransaction);
pendingTransactionIterator.remove();
}
if (firstError != null) {
throw new FlinkRuntimeException("Committing one of transactions failed, logging first encountered failure",
firstError);
}
}
|
该方法每次从正在等待提交的事务句柄中取出一个,校验它的检查点ID,并调用commit()方法提交之。这阶段的流程可以用下图来表示:
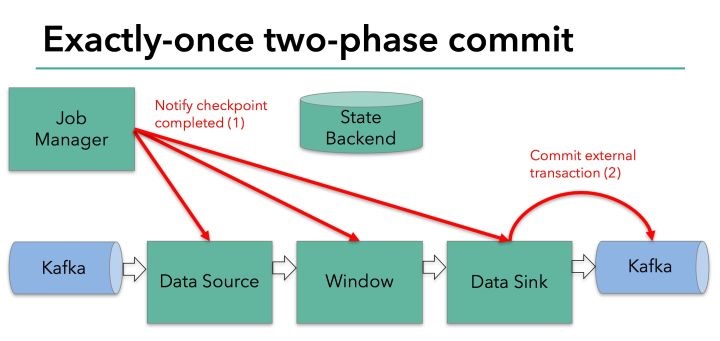
可见,只有在所有检查点都成功完成这个前提下,写入才会成功。这符合前文所述2PC的流程,其中JobManager为协调者,各个算子为参与者(不过只有sink一个参与者会执行提交)。一旦有检查点失败,notifyCheckpointComplete()方法就不会执行。如果重试也不成功的话,最终会调用abort()方法回滚事务。
1
2
3
4
5
6
7
| @Override
protected void abort(KafkaTransactionState transaction) {
if (transaction.isTransactional()) {
transaction.producer.abortTransaction();
recycleTransactionalProducer(transaction.producer);
}
}
|
4. 2PC的缺点
- 协调者存在单点问题。如果协调者挂了,整个2PC逻辑就彻底不能运行。
- 执行过程是完全同步的。各参与者在等待其他参与者响应的过程中都处于阻塞状态,大并发下有性能问题。
- 仍然存在不一致风险。如果由于网络异常等意外导致只有部分参与者收到了commit请求,就会造成部分参与者提交了事务而其他参与者未提交的情况。