Flink结合Kafka实现端到端的一致性
1. 流计算中的一致性语义
- 典型的流计算场景图示
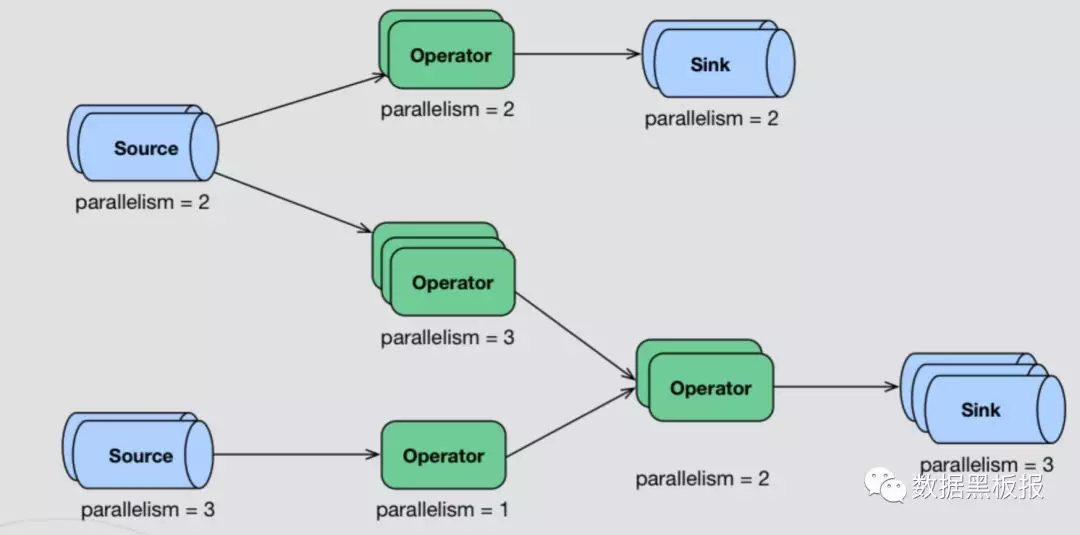
- 典型的流计算场景说明
- 一般流计算的典型场景都是如上图所示这一类的,分布式情况下是由多个Source(读取数据)节点、多个Operator(数据处理)节点、多个Sink(输出)节点组成。
- 每个节点的并行数可以不一致,且每个节点都有可能发生故障或存在网络问题。
- 保证数据准确性最重要的一点,就是当发生故障时,系统是如何容错与恢复的。
- 最简单的一种错误修复方式:At Most Once
- 当节点发生故障,故障恢复重新启动后,直接从下个数据处理,之前错误的数据就不管了。
- 最多计算一次,该方式适用于一致性要求没那么高的业务场景,如下图所示。

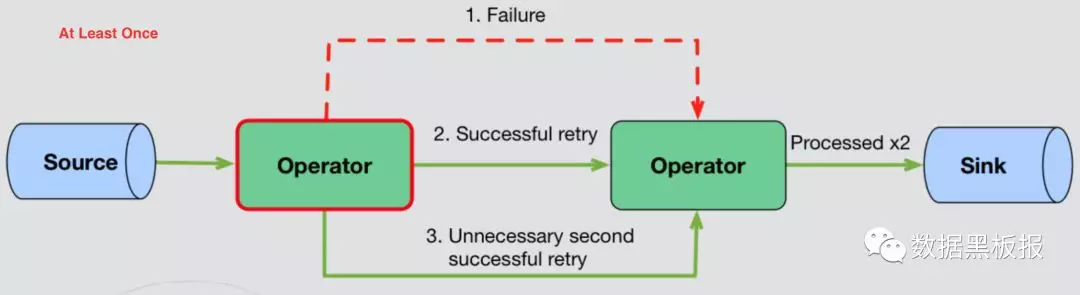
随着对计算准确性要求变高:At Least Once
- 当节点发生故障,故障恢复重新启动后,只要进行重试就可以了。
- 至少计算一次,发生故障后,只要重试就可以了,至于有没有重复数据,不会关心,所以这种场景一般需要人工自己处理重复数据,如下图所示。
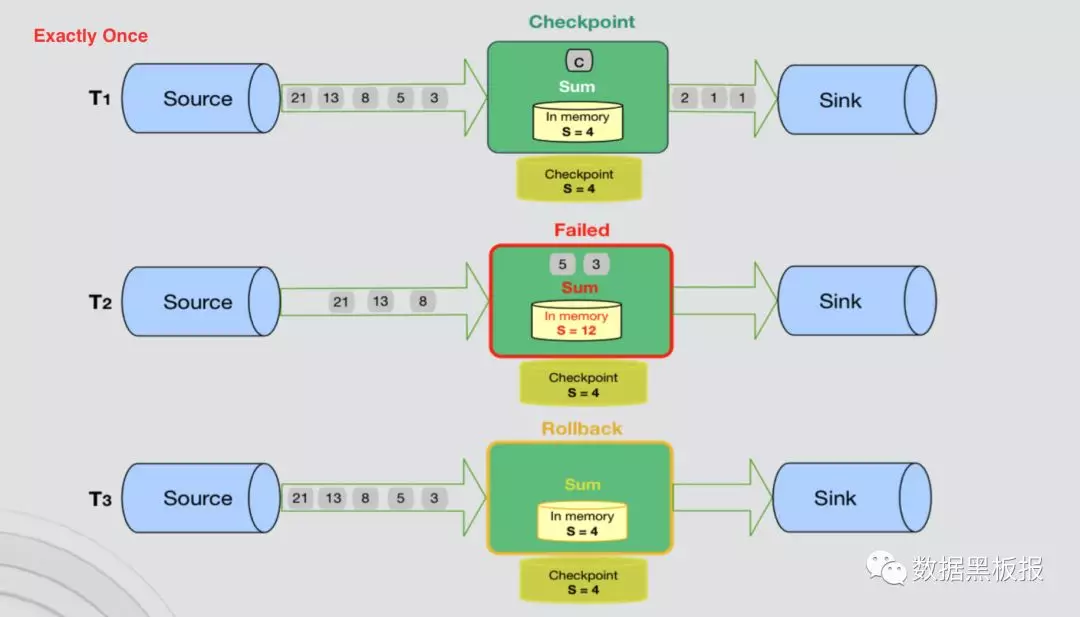
要求更精确的计算:Exactly Once
- 在计算过程中,可以将计算节点状态,保存在状态存储中,当节点发生故障时,可以从保存的状态中恢复。
- 精确计算一次,只能保证内部系统的精确一次计算,无法保证外部系统也是精确一次。
- 比如Flink计算节点故障,这个期间可能已经有一部分数据Sink出去了,计算节点从保存的状态恢复后,就会产生重复数据。
- Exactly Once 如下图所示。
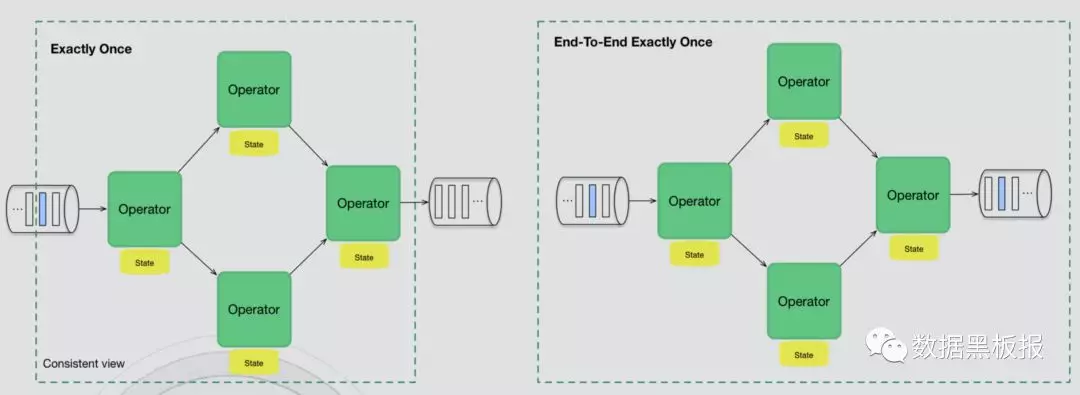
端到端的一致性语义:End-To-End Exactly Once
- 在Flink系统中,实现端到端的一致性语义是通过Flink-Kafka实现的。
- 保证所有记录仅影响内部和外部状态一次。
- 与Exactly Once对比如图所示。
End-To-End Exactly Once 的一种副作用
- 比如在Operator中有一个全局的计数器,当发生故障并恢复后,这个计数器其实是不准确的; 再比如服务中有一个GUID,这个全局唯一标识在发生故障后,其实是浪费掉了。
- 上述的全局问题,很难解决,然而目前使用Flink计算,并不关心这类问题。
2. 流计算系统如何支持一致性语义
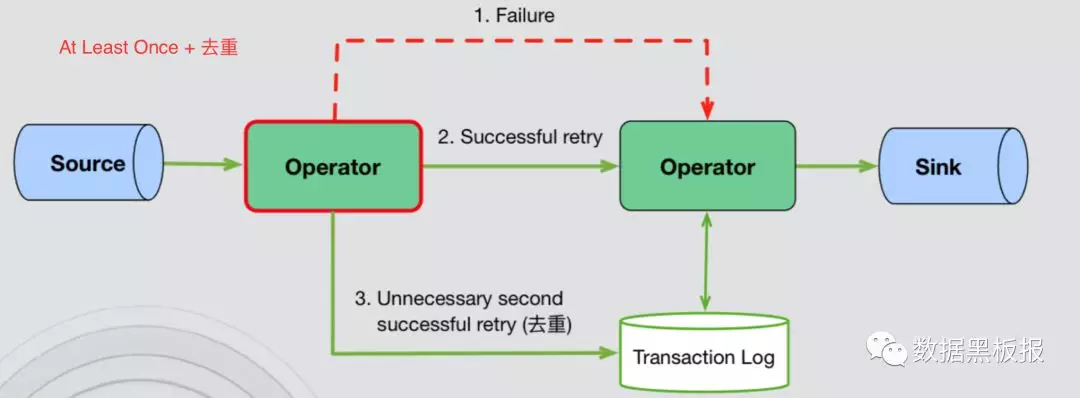
- At Least Once + 去重
- 每个算子维护一个事务日志,跟踪已处理的事件,重放失败的事件,在事件进入下个算子之前,移除重复事件。
- 优点:故障对性能影响是局部的; 故障的影响不一定会随着拓扑的大小而增加。
- 缺点:可能需要大量的存储和基础设施来支持; 每个算子的每个事件都有性能开销。
- 实现方式如下图所示。
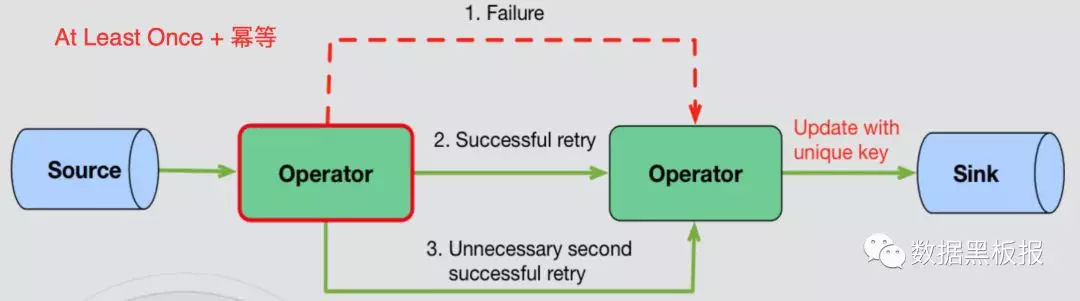
At Least Once + 幂等
- 依赖Sink端的存储与特性,不停的Update,比如Sink到HBase,但是这种方式不适合我们目前的场景,因为我们目前存储使用Druid,Druid做更新操作是比较困难的,每次更新需要重新生成segment,开销很大。
- 优点:实现简单、开销较低。
- 缺点:依赖存储特性和数据特征。
- 实现方式如下图所示。
分布式快照算法(异步屏障快照)
- 引入Barrier,把输入的数据流分为两部分:preshot records和postshot records。
- Operator收割所有上游Barrier的时候做一个snapshot,存储在内部的state backend里面。
- 当所有Sink Operator都完成了snapshot,这一轮snapshot就完成了。
- 优点:较小的性能和资源开销。
- 缺点:Barrier同步; 任何算子发生故障,都需要发生全局暂停和状态回滚; 拓扑越大,对性能的潜在影响越大。
- 实现方式如下图所示。
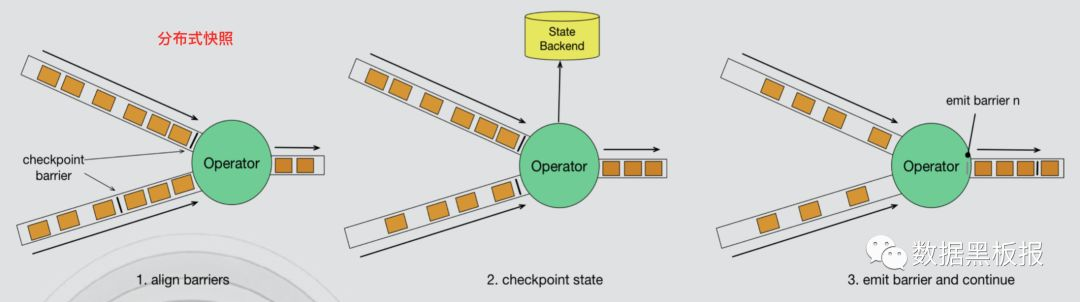
小贴士: 什么是Barrier(屏障) 与 异步屏障快照?
- 屏障是一种特殊的内部消息,用于将数据流从时间上切分为多个窗口,每个窗口对应一系列连续的快照中的一个。
- 屏障由 JobManager 定时广播给计算任务所有的 Source,其后伴随数据流一起流至下游。每个 barrier 是属于当前快照的数据与属于下个快照的数据的分割点。
- 异步屏障快照是一种轻量级的快照技术,能以低成本备份计算作业的状态,这使得计算作业可以频繁进行快照并且不会对性能产生明显影响。
- 异步屏障快照核心思想是通过屏障消息(Barrier)来标记触发快照的时间点和对应的数据,从而将数据流和快照时间解耦以实现异步快照操作。
3. Flink + Kafka 如何实现End-To-End Exactly Once
Flink 对Exactly Once的支持
- Flink 1.4版本之前,支持Exactly Once语义,仅限于应用程序内部。
- Flink 1.4版本之后,通过两阶段提交(TwoPhaseCommitSinkFunction)支持End-To-End Exactly Once,并且要求Kafka 0.11+。
- 使用TwoPhaseCommitSinkFunction是通用的解决方案,只要实现对应的接口,并且Sink的存储支持事务提交,即可实现端到端的一致性语义。
TwoPhaseCommitSinkFunction 接口
CheckpointFunction
实现两个方法:initializeState、snapshotState,
给state一个初始值,设置snapshot需要保存什么数据。
CheckpointListener
在整个checkpoint完成时,会执行回调方法notifyCheckpointComplete。
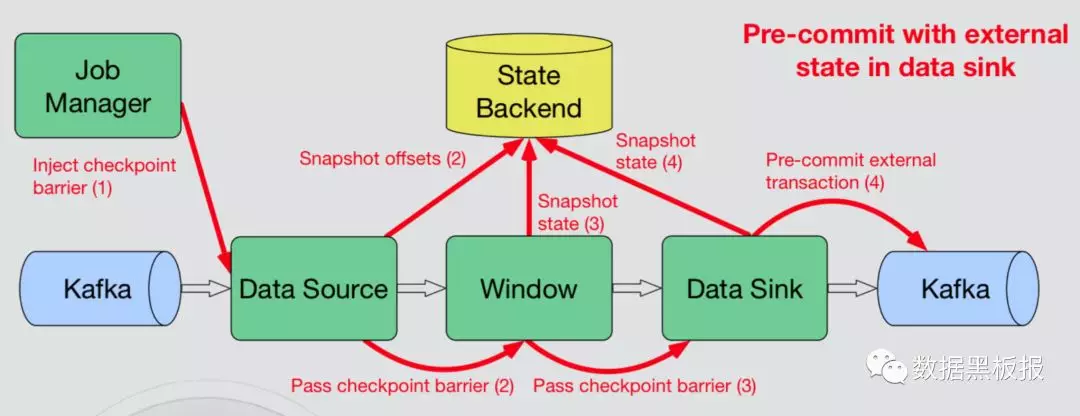
Exactly Once two-phase commit (两阶段提交)
- 当checkpoint启动后,JobManager会统一发消息给Source节点,统一下发Barrier给所有的Source。
- Barrier和数据没什么区别,只是用来将数据切分为两部分,Barrier前与Barrier后。
- 当Source收到所有的上游Barrier后(这步也叫做Barrier对齐),Source会发出新的Barrier给window算子,并将内部状态保存至state backend。
- 后续除了Sink的所有节点也按照上述的逻辑进行,Barrier对齐,Barrier发送,存储内部状态。
- 一旦有任何一个节点有失败,则回滚到上一次做的checkpoint位置。
- Sink节点Barrier对齐后,会做Pre-commit,往Kafka提交一个Pre-commit事务,然后再把Sink内部状态保存到state backend。
- 当所有的Sink节点都完成之后,会往JobManager发消息,JobManager收到消息之后,认为这一次checkpoint完成,JobManager会往下面所有的Operator发送消息,当所有的下游节点收到消息后,内部触发notifyCheckpointComplete方法调用,Sink节点开始做Commit操作,真正的提交事务,完成两阶段提交。
- Pre-commit与Commit如下图所示。
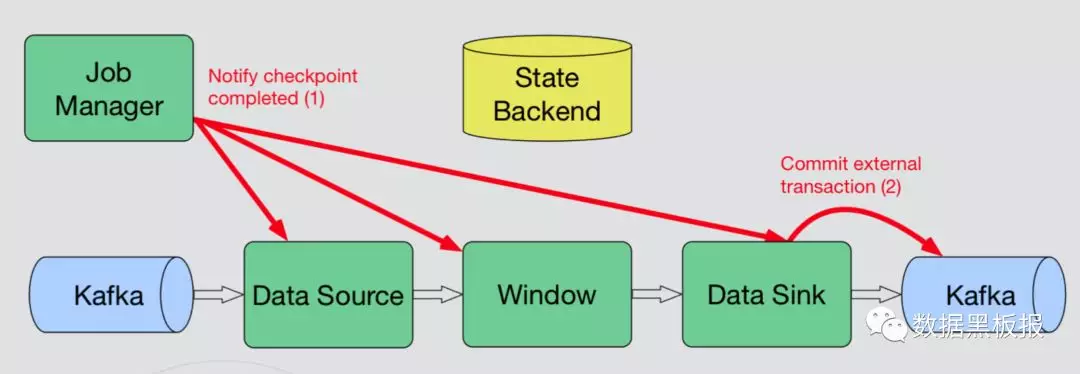
两阶段提交时发生故障的两种场景与解决方式
- 如果故障发生在Pre-commit之前,比较好处理,任务会自动回滚到上一次的checkpoint,重新执行。
- 如果故障发生在JobManager已经下发checkpoint完成的消息给Operator之后(即将或者已经触发notifyCheckpointComplete方法),虽然这个时间特别短暂,但是就在这个期间发生故障,那么数据就会有问题。而这个问题如何避免呢?在Flink的源码里面notifyCheckpointComplete方法上有这样一段注释:Note that any exception during this method will not cause the checkpoint to fail any more 意思就是说,当这个方法执行期间存在或者发生异常的时候,Flink会认为checkpoint是正常完成的,不会去做回滚等异常处理操作。所以在第二步commit上,用户需要尽量保证这步完全成功,如果发生失败,Flink并不会触发checkpoint failed,Flink官方文档给出两个建议:进行不停的重试或加入日志记录,由用户自己保证提交的成功。
4. 我们的实现方案
实现流程
- Canal订阅上游商家中心数据库变更信息到Kafka集群。
- Flink消费Kafka集群数据,进行一定程度的脏数据过滤,保障数据质量。
- 经过关联计算后的数据输出到Kafka集群。
- 使用Druid主动摄取Kafka数据进行预聚合并存储。
- 使用Superset做数据展示。
- 流程图如下。

遇到的问题
Kafka-acks超时
数据写入Kafka后,Kafka会反馈数据写入成功的消息,有时会在这里出现超时情况,因为高峰期处理的数据量较大加上网络延迟等因素有可能会导致一批反馈消息的回传时间超过默认时间(30秒),所以将默认超时时间调整为300秒,问题解决。
设置了checkpoint,执行时总出现失败,界面展示的数据卡住不动了
经过一番排查,发现任务在做checkpoint的时候,时间比较久,导致checkpoint超时失败,所以调整了做checkpoint的时间间隔为20秒,每次checkpoint超时时间为900秒,问题解决。
数据无法写入Druid
上面也讲过,实现端到端的一致性语义需要Sink端的数据库开启支持预提交操作,Druid在0.12版本还不支持这种方式,升级Druid到0.15后,开启支持预提交操作,问题解决。