Flink-1.12集成Hive
![]()
使用Hive构建数据仓库已经成为了比较普遍的一种解决方案。目前,一些比较常见的大数据处理引擎,都无一例外兼容Hive。Flink从1.9开始支持集成Hive,不过1.9版本为beta版,不推荐在生产环境中使用。在Flink1.10版本中,标志着对 Blink的整合宣告完成,对 Hive 的集成也达到了生产级别的要求。值得注意的是,不同版本的Flink对于Hive的集成有所差异,本文将以最新的Flink1.12版本为例,阐述Flink集成Hive的简单步骤,以下是全文,希望对你有所帮助。
1. Flink集成Hive的基本方式
Flink 与 Hive 的集成主要体现在以下两个方面:
- 持久化元数据
Flink利用 Hive 的 MetaStore 作为持久化的 Catalog,我们可通过HiveCatalog将不同会话中的 Flink 元数据存储到 Hive Metastore 中。例如,我们可以使用HiveCatalog将其 Kafka的数据源表存储在 Hive Metastore 中,这样该表的元数据信息会被持久化到Hive的MetaStore对应的元数据库中,在后续的 SQL 查询中,我们可以重复使用它们。
- 利用 Flink 来读写 Hive 的表。
Flink打通了与Hive的集成,如同使用SparkSQL或者Impala操作Hive中的数据一样,我们可以使用Flink直接读写Hive中的表。
HiveCatalog的设计提供了与 Hive 良好的兼容性,用户可以”开箱即用”的访问其已有的 Hive表。不需要修改现有的 Hive Metastore,也不需要更改表的数据位置或分区。
2. Flink集成Hive的步骤
2.1 Flink支持的Hive版本
| 大版本 | V1 | V2 | V3 | V4 | V5 | V6 | V7 |
|---|---|---|---|---|---|---|---|
| 1.0 | 1.0.0 | 1.0.1 | |||||
| 1.1 | 1.1.0 | 1.1.1 | |||||
| 1.2 | 1.2.0 | 1.2.1 | 1.2.2 | ||||
| 2.0 | 2.0.0 | 2.0.1 | |||||
| 2.1 | 2.1.0 | 2.1.1 | |||||
| 2.2 | 2.2.0 | ||||||
| 2.3 | 2.3.0 | 2.3.1 | 2.3.2 | 2.3.3 | 2.3.4 | 2.3.5 | 2.3.6 |
| 3.1 | 3.1.0 | 3.1.1 | 3.1.2 |
值得注意的是,对于不同的Hive版本,可能在功能方面有所差异,这些差异取决于你使用的Hive版本,而不取决于Flink,一些版本的功能差异如下:
- Hive 内置函数在使用 Hive-1.2.0 及更高版本时支持。
- 列约束,也就是 PRIMARY KEY 和 NOT NULL,在使用 Hive-3.1.0 及更高版本时支持。
- 更改表的统计信息,在使用 Hive-1.2.0 及更高版本时支持。
DATE列统计信息,在使用 Hive-1.2.0 及更高版时支持。- 使用 Hive-2.0.x 版本时不支持写入 ORC 表。
2.2 依赖项
本文以Flink1.12为例,集成的Hive版本为Hive2.3.4。集成Hive需要额外添加一些依赖jar包,并将其放置在Flink安装目录下的lib文件夹下,这样我们才能通过 Table API 或 SQL Client 与 Hive 进行交互。
另外,Apache Hive 是基于 Hadoop 之上构建的, 所以还需要 Hadoop 的依赖,配置好HADOOP_CLASSPATH即可。这一点非常重要,否则在使用FlinkSQL Cli查询Hive中的表时,会报如下错误:
1 | java.lang.ClassNotFoundException: org.apache.hadoop.mapred.JobConf |
配置HADOOP_CLASSPATH,需要在/etc/profile文件中配置如下的环境变量:
1 | export HADOOP_CLASSPATH=`hadoop classpath` |
Flink官网提供了两种方式添加Hive的依赖项。第一种是使用 Flink 提供的 Hive Jar包(根据使用的 Metastore 的版本来选择对应的 Hive jar),建议优先使用Flink提供的Hive jar包,这种方式比较简单方便。本文使用的就是此种方式。当然,如果你使用的Hive版本与Flink提供的Hive jar包兼容的版本不一致,你可以选择第二种方式,即别添加每个所需的 jar 包。
下面列举了可用的jar包及其适用的Hive版本,我们可以根据使用的Hive版本,下载对应的jar包即可。比如本文使用的Hive版本为Hive2.3.4,所以只需要下载flink-sql-connector-hive-2.3.6即可,并将其放置在Flink安装目录的lib文件夹下。
| Metastore version | Maven dependency |
|---|---|
| 1.0.0 ~ 1.2.2 | flink-sql-connector-hive-1.2.2 |
| 2.0.0 ~2.2.0 | flink-sql-connector-hive-2.2.0 |
| 2.3.0 ~2.3.6 | flink-sql-connector-hive-2.3.6 |
| 3.0.0 ~ 3.1.2 | flink-sql-connector-hive-3.1.2 |
上面列举的jar包,是我们在使用Flink SQL Cli所需要的jar包,除此之外,根据不同的Hive版本,还需要添加如下jar包。以Hive2.3.4为例,除了上面的一个jar包之外,还需要添加下面两个jar包:
flink-connector-hive_2.11-1.12.0.jar和hive-exec-2.3.4.jar。其中hive-exec-2.3.4.jar包存在于Hive安装路径下的lib文件夹。flink-connector-hive_2.11-1.12.0.jar的下载地址为:
1 | https://repo1.maven.org/maven2/org/apache/flink/flink-connector-hive_2.11/1.12.0/ |
尖叫提示:Flink1.12集成Hive只需要添加如下三个jar包,以Hive2.3.4为例,分别为:
flink-sql-connector-hive-2.3.6
flink-connector-hive_2.11-1.12.0.jar
hive-exec-2.3.4.jar
2.3 Flink SQL Cli集成Hive
将上面的三个jar包添加至Flink的lib目录下之后,就可以使用Flink操作Hive的数据表了。以FlinkSQL Cli为例:
2.4 配置sql-client-defaults.yaml
该文件时Flink SQL Cli启动时使用的配置文件,该文件位于Flink安装目录的conf/文件夹下,具体的配置如下,主要是配置catalog:
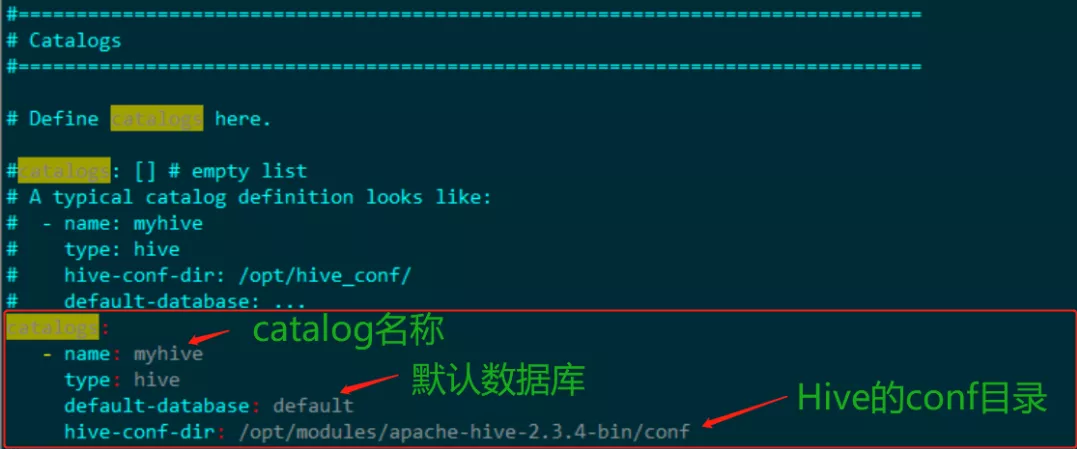
除了上面的一些配置参数,Flink还提供了下面的一些其他配置参数:
| 参数 | 必选 | 默认值 | 类型 | 描述 |
|---|---|---|---|---|
| type | 是 | (无) | String | Catalog 的类型。创建 HiveCatalog 时,该参数必须设置为'hive'。 |
| name | 是 | (无) | String | Catalog 的名字。仅在使用 YAML file 时需要指定。 |
| hive-conf-dir | 否 | (无) | String | 指向包含 hive-site.xml 目录的 URI。该 URI 必须是 Hadoop 文件系统所支持的类型。如果指定一个相对 URI,即不包含 scheme,则默认为本地文件系统。如果该参数没有指定,我们会在 class path 下查找hive-site.xml。 |
| default-database | 否 | default | String | 当一个catalog被设为当前catalog时,所使用的默认当前database。 |
| hive-version | 否 | (无) | String | HiveCatalog 能够自动检测使用的 Hive 版本。我们建议不要手动设置 Hive 版本,除非自动检测机制失败。 |
| hadoop-conf-dir | 否 | (无) | String | Hadoop 配置文件目录的路径。目前仅支持本地文件系统路径。我们推荐使用 HADOOP_CONF_DIR 环境变量来指定 Hadoop 配置。因此仅在环境变量不满足您的需求时再考虑使用该参数,例如当您希望为每个 HiveCatalog 单独设置 Hadoop 配置时。 |
2.5 操作Hive中的表
首先启动FlinkSQL Cli,命令如下:
1 | ./bin/sql-client.sh embedded |
接下来,我们可以查看注册的catalog
1 | Flink SQL> show catalogs; |
使用注册的myhive catalog
1 | Flink SQL> use catalog myhive; |
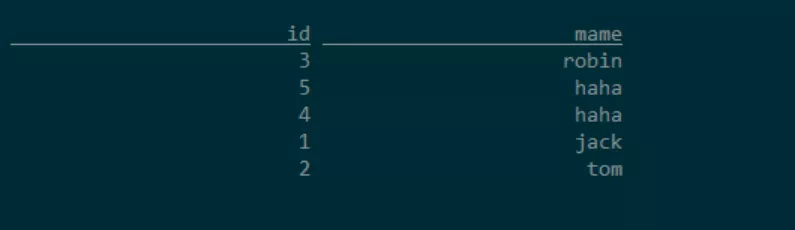
假设Hive中有一张users表,在Hive中查询该表:
1 | hive (default)> select * from users; |
查看对应的数据库表,我们可以看到Hive中已经存在的表,这样就可以使用FlinkSQL操作Hive中的表,比如查询,写入数据。
1 | Flink SQL> show tables; |
向Hive表users中插入一条数据:
1 | Flink SQL> insert into users select 6,'bob'; |
再次使用Hive客户端去查询该表的数据,会发现写入了一条数据。
接下来,我们再在FlinkSQL Cli中创建一张kafka的数据源表:
1 | CREATE TABLE user_behavior ( |
查看表结构
1 | Flink SQL> DESCRIBE user_behavior; |

我们可以在Hive的客户端中执行下面命令查看刚刚在Flink SQLCli中创建的表
1 | hive (default)> desc formatted user_behavior; |
尖叫提示:在Flink中创建一张表,会把该表的元数据信息持久化到Hive的metastore中,我们可以在Hive的metastore中查看该表的元数据信息
进入Hive的元数据信息库,本文使用的是MySQL。执行下面的命令:
1 | SELECT |

2.6 使用代码连接到 Hive
maven依赖
1 | <!-- Flink Dependency --> |
代码
1 | public class HiveIntegrationDemo { |
提交程序,观察Hive表的变化:
1 | bin/flink run -m kms-1:8081 \ |
- 总结
本文以最新的Flink1.12为例,阐述了Flink集成Hive的基本步骤,并对其注意事项进行了说明。文中也给出了如何通过FlinkSQL Cli和代码去操作Hive表的步骤。