Flink-1.12流批一体时代
![]()
1. Flink1.12 Release
Apache Flink 社区很荣幸地宣布 Flink 1.12.0 版本正式发布!近 300 位贡献者参与了 Flink 1.12.0 的开发,提交了超过 1000 多个修复或优化。这些修改极大地提高了 Flink 的可用性,并且简化(且统一)了 Flink 的整个 API 栈。其中一些比较重要的修改包括:
- 在 DataStream API 上添加了高效的批执行模式的支持,这是批处理和流处理实现真正统一的运行时的一个重要里程碑。
- 实现了基于Kubernetes的高可用性(HA)方案,作为生产环境中,ZooKeeper方案之外的另外一种选择。
- 扩展了 Kafka SQL connector,使其可以在 upsert 模式下工作,并且支持在 SQL DDL 中处理 connector 的 metadata。现在,时态表 Join 可以完全用 SQL 来表示,不再依赖于 Table API 了。
- PyFlink 中添加了对于 DataStream API 的支持,将 PyFlink 扩展到了更复杂的场景,比如需要对状态或者定时器 timer 进行细粒度控制的场景。除此之外,现在原生支持将 PyFlink 作业部署到 Kubernetes上。
2. 新的功能和优化
2.1 DataStream API 支持批执行模式
Flink 的核心 API 最初是针对特定的场景设计的,尽管 Table API / SQL 针对流处理和批处理已经实现了统一的 API,但当用户使用较底层的 API 时,仍然需要在批处理(DataSet API)和流处理(DataStream API)这两种不同的 API 之间进行选择。鉴于批处理是流处理的一种特例,将这两种 API 合并成统一的 API,有一些非常明显的好处,比如:
- 可复用性:作业可以在流和批这两种执行模式之间自由地切换,而无需重写任何代码。因此,用户可以复用同一个作业,来处理实时数据和历史数据。
- 维护简单:统一的 API 意味着流和批可以共用同一组 connector,维护同一套代码,并能够轻松地实现流批混合执行,例如 backfilling 之类的场景。
- 考虑到这些优点,社区已朝着流批统一的 DataStream API 迈出了第一步:支持高效的批处理(FLIP-134)。从长远来看,这意味着 DataSet API 将被弃用(FLIP-131),其功能将被包含在 DataStream API 和 Table API / SQL 中。
有限流上的批处理
您已经可以使用 DataStream API 来处理有限流(例如文件)了,但需要注意的是,运行时并不“知道”作业的输入是有限的。为了优化在有限流情况下运行时的执行性能,新的 BATCH 执行模式,对于聚合操作,全部在内存中进行,且使用 sort-based shuffle(FLIP-140)和优化过的调度策略(请参见 Pipelined Region Scheduling 了解更多详细信息)。因此,DataStream API 中的 BATCH 执行模式已经非常接近 Flink 1.12 中 DataSet API 的性能。有关性能的更多详细信息,请查看 FLIP-140。
在 Flink 1.12 中,默认执行模式为 STREAMING,要将作业配置为以 BATCH 模式运行,可以在提交作业的时候,设置参数 execution.runtime-mode:
1 | $ bin/flink run -Dexecution.runtime-mode=BATCH examples/streaming/WordCount.jar |
或者通过编程的方式:
1 | StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); |
注意:尽管 DataSet API 尚未被弃用,但我们建议用户优先使用具有 BATCH 执行模式的 DataStream API 来开发新的批作业,并考虑迁移现有的 DataSet 作业。
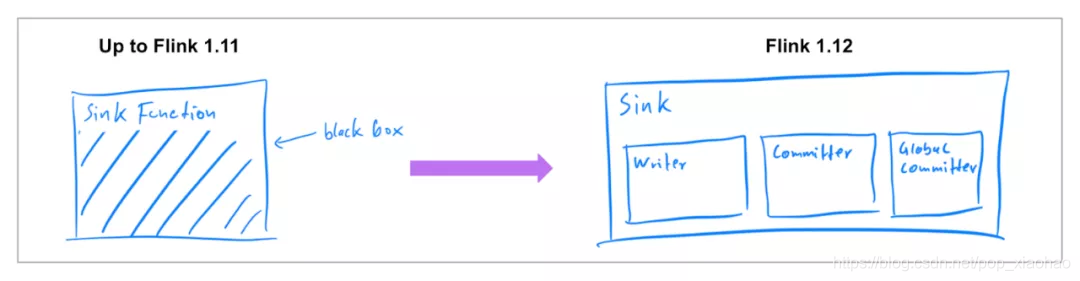
2.2 新的 Data Sink API (Beta)
之前发布的 Flink 版本中,已经支持了 source connector 工作在流批两种模式下,因此在 Flink 1.12 中,社区着重实现了统一的 Data Sink API(FLIP-143)。新的抽象引入了 write/commit 协议和一个更加模块化的接口。Sink 的实现者只需要定义 what 和 how:SinkWriter,用于写数据,并输出需要 commit 的内容(例如,committables);Committer 和 GlobalCommitter,封装了如何处理 committables。框架会负责 when 和 where:即在什么时间,以及在哪些机器或进程中 commit。
2.3 基于 Kubernetes 的高可用 (HA) 方案
Flink 可以利用 Kubernetes 提供的内置功能来实现 JobManager 的 failover,而不用依赖 ZooKeeper。为了实现不依赖于 ZooKeeper 的高可用方案,社区在 Flink 1.12(FLIP-144)中实现了基于 Kubernetes 的高可用方案。该方案与 ZooKeeper 方案基于相同的接口[3],并使用 Kubernetes 的 ConfigMap[4] 对象来处理从 JobManager 的故障中恢复所需的所有元数据。关于如何配置高可用的 standalone 或原生 Kubernetes 集群的更多详细信息和示例,请查阅文档[5]。
注意:需要注意的是,这并不意味着 ZooKeeper 将被删除,这只是为 Kubernetes 上的 Flink 用户提供了另外一种选择。
2.4 其他改变
将现有的 connector 迁移到新的 Data Source API
在之前的版本中,Flink 引入了新的 Data Source API(FLIP-27),以允许实现同时适用于有限数据(批)作业和无限数据(流)作业使用的 connector 。在 Flink 1.12 中,社区从 FileSystem connector(FLINK-19161)出发,开始将现有的 source connector 移植到新的接口。
注意: 新的 source 实现,是完全不同的实现,与旧版本的实现不兼容。
Pipelined Region 调度 (FLIP-119)
在之前的版本中,Flink 对于批作业和流作业有两套独立的调度策略。Flink 1.12 版本中,引入了统一的调度策略, 该策略通过识别 blocking 数据传输边,将 ExecutionGraph 分解为多个 pipelined region。这样一来,对于一个 pipelined region 来说,仅当有数据时才调度它,并且仅在所有其所需的资源都被满足时才部署它;同时也可以支持独立地重启失败的 region。对于批作业来说,新策略可显著地提高资源利用率,并消除死锁。
支持 Sort-Merge Shuffle (FLIP-148)
为了提高大规模批作业的稳定性、性能和资源利用率,社区引入了 sort-merge shuffle,以替代 Flink 现有的实现。这种方案可以显著减少 shuffle 的时间,并使用较少的文件句柄和文件写缓存(这对于大规模批作业的执行非常重要)。在后续版本中(FLINK-19614),Flink 会进一步优化相关性能。
注意:该功能是实验性的,在 Flink 1.12 中默认情况下不启用。要启用 sort-merge shuffle,需要在 TaskManager 的网络配置[6]中设置合理的最小并行度。
Flink WebUI 的改进 (FLIP-75)
作为对上一个版本中,Flink WebUI 一系列改进的延续,Flink 1.12 在 WebUI 上暴露了 JobManager 内存相关的指标和配置参数(FLIP-104)。对于 TaskManager 的指标页面也进行了更新,为 Managed Memory、Network Memory 和 Metaspace 添加了新的指标,以反映自 Flink 1.10(FLIP-102)开始引入的 TaskManager 内存模型的更改[7]。
Table API/SQL: SQL Connectors 中的 Metadata 处理
如果可以将某些 source(和 format)的元数据作为额外字段暴露给用户,对于需要将元数据与记录数据一起处理的用户来说很有意义。一个常见的例子是 Kafka,用户可能需要访问 offset、partition 或 topic 信息、读写 kafka 消息中的 key 或 使用消息 metadata中的时间戳进行时间相关的操作。
在 Flink 1.12 中,Flink SQL 支持了元数据列用来读取和写入每行数据中 connector 或 format 相关的列(FLIP-107)。这些列在 CREATE TABLE 语句中使用 METADATA(保留)关键字来声明。上面的示例同时也展示了如何在 temporal table join 中使用 Flink 1.12 中新增的 upsert-kafka connector。
1
2
3
4
5
6
7
8
9
10
11CREATE TABLE kafka_table (
id BIGINT,
name STRING,
event_time TIMESTAMP(3) METADATA FROM 'timestamp', -- access Kafka 'timestamp' metadata
headers MAP<STRING, BYTES> METADATA -- access Kafka 'headers' metadata
) WITH (
'connector' = 'kafka',
'topic' = 'test-topic',
'format' = 'avro'
);
12345678910在 Flink 1.12 中,已经支持 Kafka 和 Kinesis connector 的元数据,并且 FileSystem connector 上的相关工作也已经在计划中(FLINK-19903)。由于 Kafka record 的结构比较复杂,社区还专门为 Kafka connector 实现了新的属性[8],以控制如何处理键/值对。关于 Flink SQL 中元数据支持的完整描述,请查看每个 connector 的文档[9]以及 FLIP-107 中描述的用例。
Table API/SQL: Upsert Kafka Connector
在某些场景中,例如读取 compacted topic 或者输出(更新)聚合结果的时候,需要将 Kafka 消息记录的 key 当成主键处理,用来确定一条数据是应该作为插入、删除还是更新记录来处理。为了实现该功能,社区为 Kafka 专门新增了一个 upsert connector(upsert-kafka),该 connector 扩展自现有的 Kafka connector,工作在 upsert 模式(FLIP-149)下。新的 upsert-kafka connector 既可以作为 source 使用,也可以作为 sink 使用,并且提供了与现有的 kafka connector 相同的基本功能和持久性保证,因为两者之间复用了大部分代码。
要使用 upsert-kafka connector,必须在创建表时定义主键,并为键(key.format)和值(value.format)指定序列化反序列化格式。完整的示例,请查看最新的文档[10]。
Table API/SQL: SQL 中 支持 Temporal Table Join
在之前的版本中,用户需要通过创建时态表函数(temporal table function) 来支持时态表 join(temporal table join) ,而在 Flink 1.12 中,用户可以使用标准的 SQL 语句 FOR SYSTEM_TIME AS OF(SQL:2011)来支持 join。此外,现在任意包含时间列和主键的表,都可以作为时态表,而不仅仅是 append-only 表。这带来了一些新的应用场景,比如将 Kafka compacted topic 或数据库变更日志(来自 Debezium 等)作为时态表。
1 | CREATE TABLE orders ( |
使用 Hive 表进行 Temporal Table Join
用户也可以将 Hive 表作为时态表来使用,Flink 既支持自动读取 Hive 表的最新分区作为时态表(FLINK-19644),也支持在作业执行时追踪整个 Hive 表的最新版本作为时态表。请参阅文档,了解更多关于如何在 temporal table join 中使用 Hive 表的示例。