使用hexo,如果换了电脑怎么更新博客

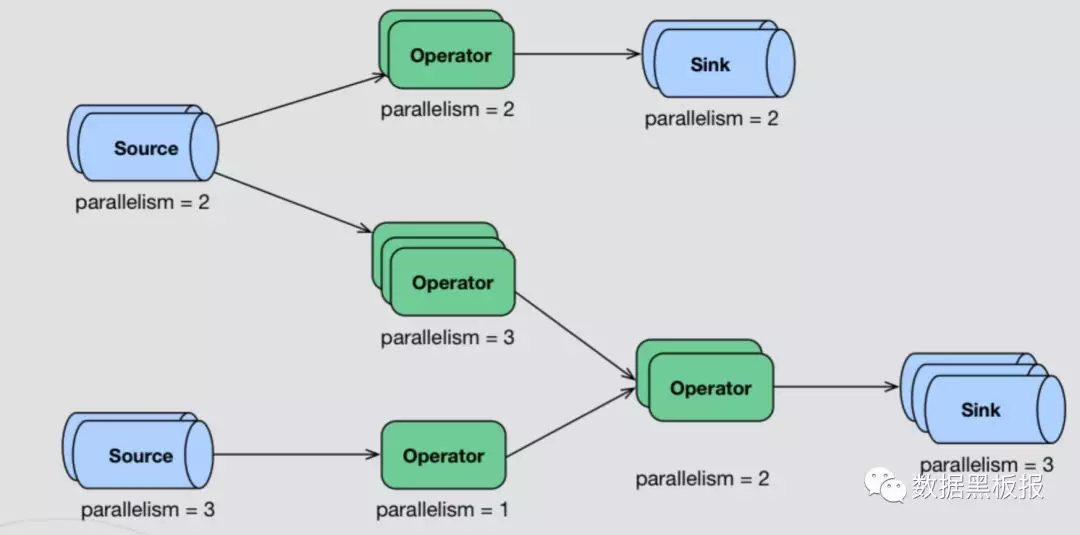
Flink常用算子
![]()
Flink和Spark类似,也是一种一站式处理的框架;既可以进行批处理(DataSet),也可以进行实时处理(DataStream)。
所以下面将Flink的算子分为两大类:DataSet和DataStream,下面将对这两大类的API以及用法展开分析:
Spark分区管理
当我们使用Spark加载数据源并进行一些列转换时,Spark会将数据拆分为多个分区Partition,并在分区上并行执行计算。所以理解Spark是如何对数据进行分区的以及何时需要手动调整Spark的分区,可以帮助我们提升Spark程序的运行效率。
你必须Get的开源CDC技术[Debezium]

Exactly_Once到底是什么-Ⅱ
分布式事件流处理正逐渐成为大数据领域中一个热门话题。著名的流处理引擎(Streaming Processing Engines, SPEs)包括Apache Storm、Apache Flink、Heron、Apache Kafka(Kafka Streams)以及Apache Spark(Spark Streaming)。流处理引擎中一个著名的且经常被广泛讨论的特征是它们的处理语义,而“exactly-once”是其中最受欢迎的,同时也有很多引擎声称它们提供“exactly-once”处理语义。
Flink-SQL-CDC实践及一致性的分析
什么是两阶段提交
在分布式系统中,为了让每个节点都能够感知到其他节点的事务执行状况,需要引入一个中心节点来统一处理所有节点的执行逻辑,这个中心节点叫做协调者(coordinator),被中心节点调度的其他业务节点叫做参与者(participant)。
接下来正式介绍2PC。顾名思义,2PC将分布式事务分成了两个阶段,两个阶段分别为提交请求(投票)和提交(执行)。协调者根据参与者的响应来决定是否需要真正地执行事务,具体流程如下。
深入理解Flink_end-to-end_exactly-once语义
上一篇文章所述的Exactly-Once语义是针对Flink系统内部而言的.
那么Flink和外部系统(如Kafka)之间的消息传递如何做到exactly once呢?